


For Every Business, As data science workflows become increasingly complex and datasets grow in size, traditional single-machine computing becomes a bottleneck. The ability to distribute computation across multiple machines or processes is crucial for efficiently handling large-scale data analysis. This is where Distributed Computing with R comes in, with its wide array of packages and tools, provides powerful solutions for scaling computations across multiple cores or even clusters of machines.
In this blog post, we’ll dive into distributed computing with R, explore the tools and packages that make it possible, and show how you can harness parallelism for high-performance data analysis.
What is Distributed Computing?

Distributed Computing with R refers to a system where multiple computers (or nodes) work together to solve a problem. In the context of data science, this means breaking down large computational tasks into smaller sub-tasks that can be executed simultaneously across different machines or processors. The results from each node are then combined to provide the final output.
This approach can drastically reduce computation time, particularly when working with massive datasets or complex models, making it an essential skill for modern data scientists.
Why Use Distributed Computing in R?
Distributed computing in R allows data scientists to: (Ref: Debugging Techniques in R: Troubleshoot Your Code)
- Handle large datasets that exceed the memory of a single machine.
- Speed up computations by leveraging multiple processors or machines in parallel.
- Perform real-time analytics using distributed processing platforms like Spark or Hadoop.
- Scale machine learning models efficiently by splitting the workload and processing data in parallel.
By distributing tasks across multiple machines or cores, R can handle larger data sizes and more complex computations, ensuring your analysis is both efficient and scalable.
Key Tools for Distributed Computing in R
Several R packages facilitate distributed computing, each with different strengths and use cases. Let’s look at some of the most widely used ones:
1. Parallel Package
The parallel package is a part of R’s base distribution and provides the functionality to run R code on multiple processors within a single machine. It allows you to split tasks into smaller chunks and execute them simultaneously.
- Key Functions:
mclapply(): Applies a function in parallel to a list or vector using multiple cores.parLapply(): Similar tomclapply(), but for use with parallel clusters.makeCluster(): Creates a cluster of R processes for parallel computing.
Example:

2. foreach and doParallel
The foreach package allows you to execute loops in parallel. Distributed Computing with R Combined with the doParallel package, it enables parallelization of loops and other iterative tasks.
- Key Functions:
foreach(): Performs loop iterations in parallel.registerDoParallel(): Registers a parallel backend forforeach().
Example:

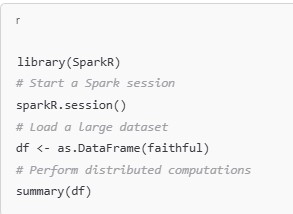
3. SparkR
For large-scale distributed computing across multiple machines, R integrates well with Apache Spark through the SparkR package. Spark is a powerful, fast, and general-purpose cluster-computing system that is highly effective for big data processing.
- Key Functions:
sparkR.session(): Starts a Spark session in R.spark.apply(): Applies a function to data in a distributed manner.
Example:
4. rhadoop and rhbase
For users who need to connect R to Hadoop, the rhadoop and rhbase packages provide an interface to work with the Hadoop ecosystem, including HDFS (Hadoop Distributed File System) and HBase.
- Key Functions:
rhbase: Connects R with HBase, a distributed NoSQL database.rmr2: A package for working with Hadoop MapReduce jobs.
Distributed Computing with R in Practice
Let’s explore a practical example where we use distributed computing to process a large dataset. Imagine we have a large CSV file with millions of rows, and we want to calculate the mean of a particular column.
Step 1: Read Data in Parallel
Instead of loading the entire dataset into memory, we can read it in chunks and process each chunk in parallel. This way, we avoid memory limitations and speed up processing.
Example:
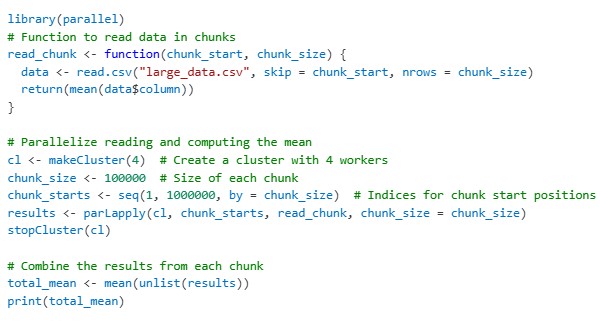
In this example, we divide the file into smaller chunks, calculate the mean for each chunk in parallel, and then combine the results.
Best Practices for Distributed Computing in R
To make the most out of distributed computing in R, consider the following best practices:
- Minimize Data Transfer: When working with distributed systems, avoid transferring large amounts of data between nodes. Instead, aim to keep the data local to each node.
- Use Efficient Algorithms: Choose algorithms that can be parallelized and are designed to work efficiently with distributed data.
- Monitor Resource Usage: Keep an eye on resource utilization, including memory and CPU, to avoid overloading the system.
- Test and Debug: Distributed computing can introduce complexities in terms of debugging and error handling. Test your code thoroughly and use appropriate logging to monitor performance.
Final Thoughts
Distributed Computing with R is an essential technique for handling big data and scaling data science workflows in R. By leveraging tools like the parallel, foreach, and SparkR packages, R users can unlock the power of parallelism and distributed systems to process large datasets faster and more efficiently.
Whether you’re working with large-scale data, complex models, or real-time analytics, R’s distributed computing capabilities provide the flexibility and power needed to tackle challenging data science tasks. With the right tools and strategies, you can harness the full potential of Distributed Computing with R to perform high-performance data analysis on a global scale. (Ref: Locus IT Services)