

For Every Business, As datasets grow larger and computational tasks become more complex, the need for faster and more efficient processing has never been more pressing. For R users, one powerful way to address these challenges is through Parallel Computing in R. By leveraging multiple processors or cores simultaneously, parallel computing can significantly speed up data analysis, simulation, and machine learning tasks.
In this blog post, we’ll explore what parallel computing is, why it matters for R programmers, and how you can implement it in your workflows to optimize performance.
What is Parallel Computing?

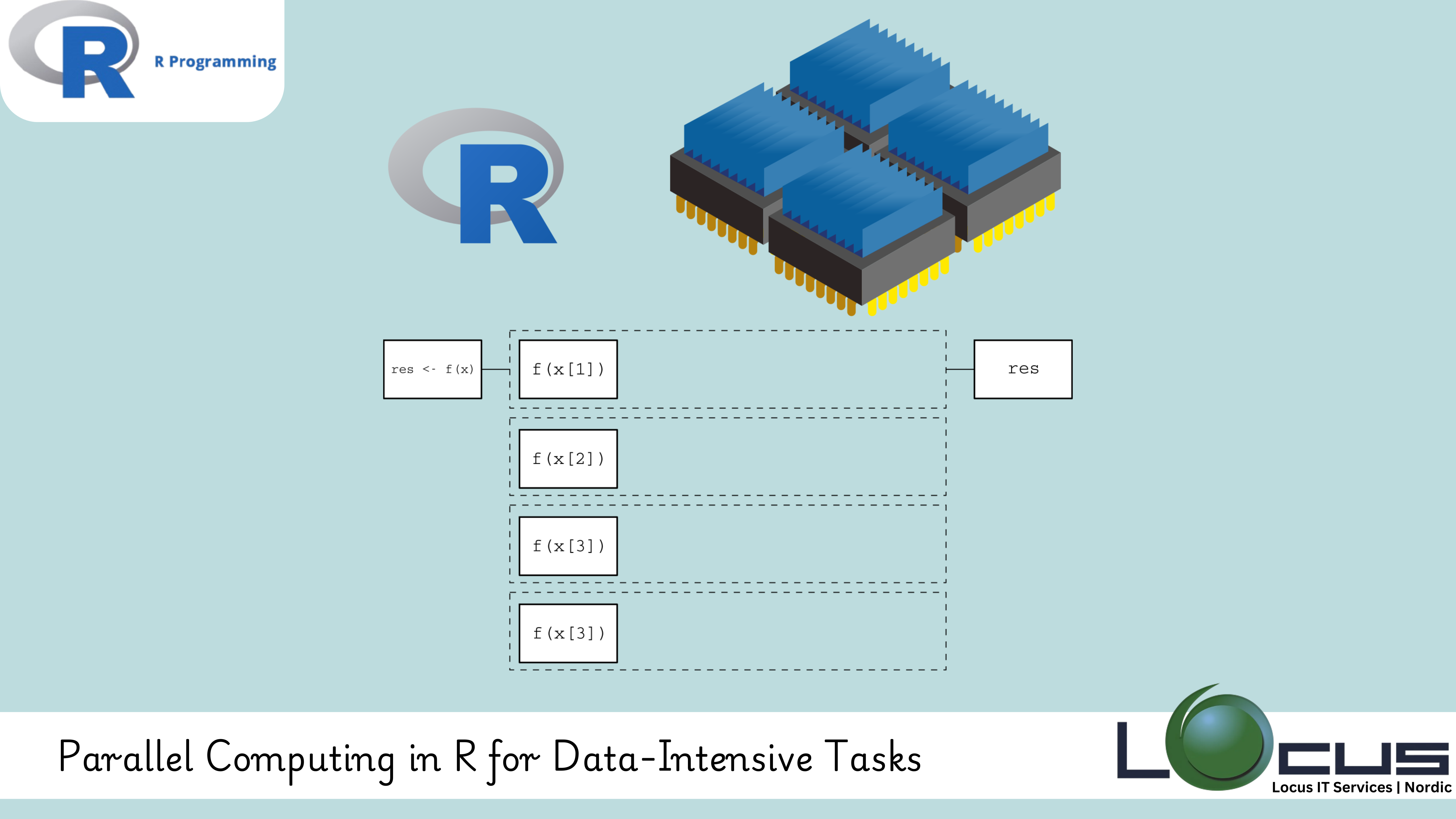
Parallel Computing in R is a method of dividing a task into smaller subtasks and executing them simultaneously on multiple processors or cores. Instead of processing tasks sequentially, parallel computing splits the workload, enabling faster execution.
In Parallel Computing in R is particularly useful for:
- Simulations: Running multiple iterations of a model simultaneously.
- Data Manipulation: Performing operations on large datasets in chunks.
- Machine Learning: Training models on distributed data or running hyperparameter tuning.
- Bootstrapping: Repeatedly sampling data and recalculating statistics. (Ref: Debugging Techniques in R: Troubleshoot Your Code)
Why Use Parallel Computing in R?
- Speed Up Computations: Tasks that take hours or even days to run sequentially can be reduced to a fraction of the time using parallel computing.
- Efficient Use of Hardware: Modern computers often come with multiple cores. Parallel Computing in R ensures you make the most of your hardware by spreading the workload across these cores.
- Scaling to Big Data: For large datasets that exceed memory limits or take too long to process, parallel computing can handle chunks of data simultaneously, reducing bottlenecks.
- Reproducibility and Flexibility: Parallel computing workflows in R are designed to be reproducible, making them suitable for research, analytics, and large-scale production tasks.
Parallel Computing Libraries in R
R provides several packages to facilitate Parallel Computing in R. Here are some of the most commonly used ones:
1. parallel
The parallel package comes bundled with R and is the foundation for most parallel computing in R. It provides functions like mclapply() and parLapply() for executing tasks in parallel.
- Best For: Tasks that can be split into independent subtasks, such as simulations or bootstrapping.
2. foreach
The foreach package is designed for iteration but can be combined with parallel backends to run tasks across multiple cores. Using it with the doParallel or doSNOW packages enables parallelism.
- Best For: Loops that are inherently parallelizable, such as applying a function to subsets of data.
3. future
The future package simplifies parallel programming by abstracting the complexities of backend selection. With functions like future_lapply() or plan(), you can seamlessly switch between sequential and parallel processing.
- Best For: Flexible parallelism across local or remote machines.
4. data.table
The data.table package includes multi-threading capabilities for data manipulation. Operations like grouping, summarizing, and filtering are optimized for parallel execution.
- Best For: High-performance data wrangling.
5. sparklyr
For big data, sparklyr integrates R with Apache Spark, allowing distributed computing across clusters.
- Best For: Large-scale data analysis and machine learning on distributed systems.
Key Concepts in Parallel Computing
1. Task Parallelism vs. Data Parallelism
- Task Parallelism: Different tasks or functions are run simultaneously. For example, running simulations with varying parameters.
- Data Parallelism: The same task is performed on chunks of data simultaneously. For example, applying a statistical model to different subsets of a dataset.
2. Explicit vs. Implicit Parallelism
- Explicit Parallelism: You explicitly define how tasks are distributed, as in
mclapply()orparLapply(). - Implicit Parallelism: Parallelization happens under the hood, such as in
data.tableordplyroperations.
3. Load Balancing
Ensuring that all cores are equally utilized is crucial for optimal performance. Uneven distribution of tasks can lead to idle cores and reduced efficiency.
4. Overhead and Scalability
While parallel computing can speed up tasks, it introduces some overhead in setting up the parallel environment and distributing tasks. For smaller tasks, the overhead might outweigh the benefits.
Examples of Parallel Computing in R
Example 1: Using parallel::mclapply()
This function applies a function to each element of a list in parallel.

Example 2: Using future for Flexible Parallelism
With future, you can easily set up parallel processing.

Best Practices for Parallel Computing in R
- Understand the Task: Not all tasks benefit from parallel computing. Ensure the task is parallelizable and justifies the additional overhead.
- Choose the Right Backend: Depending on the task, choose the appropriate package or backend (e.g.,
doParallelfor multicore processing,sparklyrfor distributed systems). - Optimize Chunk Size: Divide data into optimal-sized chunks to balance workload across cores.
- Monitor Performance: Use tools like
microbenchmarkorprofvisto measure performance and identify bottlenecks. - Handle Reproducibility: Parallel computing can introduce randomness. Use functions like
set.seed()to ensure reproducibility.
Challenges of Parallel Computing
Parallel computing offers significant advantages in terms of performance and scalability, especially for large-scale computations. However, it comes with its own set of challenges that can complicate its implementation and efficiency. Let’s break down the key challenges mentioned:
Overhead Costs
When splitting a task into multiple parallel processes, the process isn’t as straightforward as running tasks in sequence. Here’s why:
- Setup Time: Preparing the parallel environment (e.g., spawning worker processes or threads) takes time. Each worker needs to be initialized, and tasks need to be distributed among them.
- Task Distribution: Breaking a task into smaller chunks and assigning these chunks to different processors involves computational effort. Additionally, collecting and merging results from these tasks adds to the overall time.
- Communication Costs: In parallel computing, workers may need to communicate with one another or with a central node, especially in distributed systems. This data transfer can introduce latency, especially for large datasets or frequent communication.
For example, if the computational gain from parallelizing a task is small, the overhead might outweigh the benefits, making the parallel solution slower than the sequential one.
Shared Memory Issues
In shared-memory Parallel Computing in R (e.g., multiple threads accessing the same memory), managing access to shared resources becomes a critical challenge:
- Race Conditions: If two or more processes attempt to update the same variable simultaneously, it can lead to unpredictable results. For instance, if one process is reading a value while another is writing to it, the output might be inconsistent.
- Bottlenecks: Shared resources, such as memory or disk access, can become a bottleneck. Even if you have multiple processors running in Parallel Computing in R, contention for the same resource can slow down the entire computation.
- Locks and Synchronization: To prevent race conditions, mechanisms like locks, semaphores, or critical sections are used. However, these mechanisms can introduce delays (known as “lock contention”) if multiple processes are waiting for access to a locked resource.
An example is a scenario where multiple parallel threads are updating a global counter. Parallel Computing in R Without proper synchronization, the final count may be incorrect due to overlapping operations.
Debugging Parallel Code
Debugging parallel code is inherently more complex than debugging sequential code for several reasons:
- Non-Deterministic Behavior: Parallel tasks often do not execute in the same order every time. This makes it difficult to reproduce issues consistently, as bugs might only appear under specific timing conditions.
- Interdependency: Errors may arise due to interactions between processes. For example, one task might depend on the output of another, and a delay in one process can lead to failures or incorrect results in another.
- Tool Limitations: While debugging tools for sequential code are mature, tools for debugging parallel code often have limitations. It can be challenging to trace how processes interact or to identify deadlocks and race conditions.
- Deadlocks: A situation where two or more processes are waiting for each other to release resources can be hard to detect and resolve. Deadlocks often appear only under specific conditions, making them even harder to debug.
For instance, consider a parallel program where two tasks are supposed to update separate sections of an array. If one task inadvertently accesses the section assigned to another, it can lead to data corruption that’s hard to track.
Final Thoughts
Parallel computing in R is a powerful way to tackle data-intensive tasks, especially when working with large datasets or complex models. By leveraging packages like parallel, foreach, and future, you can distribute computations across multiple cores or even machines, significantly improving performance and efficiency.
With the growing demands of modern data science, mastering parallel computing in R is not just a nice-to-have skill—it’s a necessity for tackling the challenges of large-scale analysis. By implementing best practices and choosing the right tools, you can make your R scripts faster, scalable, and more efficient.
Start exploring Parallel Computing in R today, and unlock the full potential of your hardware for high-performance data analysis! (Ref: Locus IT Services)