

In Looker, data modeling is a key aspect of delivering efficient, scalable, and insightful reports and dashboards. One powerful feature within Looker’s modeling language, LookML, is the Persistent Derived Tables (PDT). PDTs allow you to create and manage complex data structures that are stored within Looker, helping you optimize query performance and manage large datasets.
In this blog post, we’ll explore what PDTs are, how to create and manage them in LookML, and best practices for ensuring they improve your data model’s efficiency and performance.
What is a Persistent Derived Table (PDT)?
A Persistent Derived Table (PDT) is a table that you define within LookML to store the results of a complex query. Unlike regular derived tables, which are recalculated with every query, PDTs are created once and stored persistently in the database, significantly improving performance by reducing the need to recalculate the same data multiple times. (Ref: Implementing Advanced Filters in LookML)
Why Use PDTs in Looker?
PDTs are particularly useful when working with large datasets, complex transformations, or when performance is a concern. Here are the main benefits of using PDTs in your Looker model:

- Improved Performance: By precomputing and persisting the results of complex queries, PDTs help avoid repetitive and costly calculations during each query run. This significantly improves the speed of dashboards and reports that rely on complex aggregations.
- Complex Data Transformations: PDTs allow you to create complex data transformations that would be inefficient or too slow to execute on-the-fly. Whether it’s combining multiple sources of data, applying advanced filtering, or performing complex aggregations, PDTs make it easier to manage these operations.
- Data Persistence: Since PDTs are stored in the database, they persist between sessions. This means that once they are generated, Looker doesn’t need to recompute the same results, thus reducing query load.
- Managing Large Datasets: When dealing with very large datasets, it’s often inefficient to query the raw data every time. PDTs provide a way to create summarized or aggregated views that are quicker to query.
How to Create and Manage PDTs in LookML
Creating a PDT in LookML is relatively straightforward, and it involves a few key steps. Let’s walk through the process:
Step 1: Define the Derived Table
A PDT is defined in LookML as a derived_table within a view. The sql parameter is where you specify the SQL query that generates the data for your table.
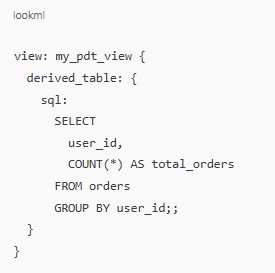
This creates a simple derived table that counts the total number of orders for each user.
Step 2: Make the Table Persistent
To ensure that your derived table is persistent, you need to set the persist_for parameter, which controls how long Looker will keep the table around before it is recomputed. This is useful for ensuring that the data is stored for a defined period, and it’s refreshed only when needed.

In this example, the PDT will be created and stored for 24 hours, after which it will be recomputed.
Step 3: Managing Refresh and Dependencies
Looker allows you to manage when and how often PDTs are refreshed. You can set refresh intervals using the persist_for parameter, but you can also trigger a refresh based on other factors, such as changes to the underlying data.
To trigger a refresh only when a table is updated, you can use the datagroup parameter, which automatically handles table refreshes based on conditions like data changes.
lookmlCopy codedatagroup: order_datagroup {
sql_trigger: SELECT MAX(updated_at) FROM orders ;;
max_cache_age: "24 hours"
}
view: my_pdt_view {
derived_table: {
sql:
SELECT
user_id,
COUNT(*) AS total_orders
FROM orders
GROUP BY user_id;;
datagroup_trigger: order_datagroup
}
}
In this case, the PDT is refreshed every 24 hours or when the orders table is updated, whichever happens first.
Step 4: Using PDTs in Explores and Queries
Once you’ve created a PDT, you can use it just like any other table in Looker. For instance, you can include the my_pdt_view in your explore to allow users to query the data and build dashboards.
lookmlCopy codeexplore: user_orders {
view_name: my_pdt_view
}
By including the view in an explore, you make the PDT available for reporting and analysis in Looker’s interface.
Best Practices for Using PDTs
While PDTs are a powerful tool for optimizing your Looker model, there are some best practices to keep in mind when using them:
- Limit the Scope of PDTs: Only create PDTs for complex or resource-intensive queries that benefit from being stored. Don’t overuse them, as maintaining too many PDTs can add overhead to your project.
- Set Appropriate Refresh Intervals: Be mindful of the refresh intervals. If your data changes frequently, you may need to refresh your Persistent Derived Tables more often. However, for data that doesn’t change as frequently, longer intervals can help reduce computational costs.
- Monitor PDT Performance: Keep an eye on the performance of your PDTs by monitoring query times and database load. If certain Persistent Derived Tables are taking longer to generate or use more resources than expected, consider optimizing the underlying SQL query.
- Avoid Unnecessary Computations: Whenever possible, try to avoid performing unnecessary computations in your Persistent Derived Tables. For example, if you need to aggregate data, do it in the most efficient way possible (e.g., use indexes and partitioning in your database).
- Understand Your Database’s Limits: Not all databases handle large volumes of data in the same way. Be sure to understand how your specific database handles temporary tables and how often it can handle large queries, especially if your Persistent Derived Tables involve a lot of data.
- Use PDTs in Combination with Caching: You can also leverage Looker’s caching capabilities alongside Persistent Derived Tables for further performance optimization. Cached queries can be served quickly, while PDTs can handle more complex data.
Troubleshooting PDTs
Like any feature in data modeling, there may be times when things go wrong. Common issues with PDTs include:
- PDTs Not Refreshing: If a PDT doesn’t refresh as expected, check that your
sql_triggerorpersist_forsettings are configured correctly. - Slow PDT Creation: Large datasets or complex queries can cause Persistent Derived Tables creation to take too long. Optimize your SQL and ensure that the underlying database is indexed appropriately.
- PDTs Not Being Available in Explores: If the Persistent Derived Tables doesn’t show up in your Explore, ensure that the
view_nameis correctly referenced and that any caching or refresh policies haven’t prevented the data from being available.
Final Thoughts
Persistent Derived Tables (PDTs) are a powerful feature in LookML that allow you to optimize the performance of your Looker models by precomputing and storing complex queries. By carefully creating and managing Persistent Derived Tables, you can significantly improve the efficiency of your reports and dashboards, especially when dealing with large datasets or complex transformations.
With best practices like setting appropriate refresh intervals, monitoring performance, and avoiding unnecessary computations, you can fully harness the potential of Persistent Derived Tables in Looker and ensure that your data models are both scalable and efficient. If used effectively, Persistent Derived Tables will become an essential tool in your Looker modeling toolkit.