

For Every Business, Statistics is the foundation of data analysis and decision-making. With Java’s robust capabilities and vast library ecosystem, you can efficiently perform statistical computations for various applications, from academic research to large-scale data processing. This blog post explores how to implement basic statistical operations in Java, including mean, median, variance, and standard deviation, using both core Java and popular libraries.
Why Use Java for Statistical Operations?

Java’s performance, portability, and extensive third-party library support make it a powerful tool for statistical operations. Here are a few reasons to choose Java for such tasks: (Ref: Interactive Data Visualization with Java)
- Speed and Efficiency: Java’s performance is well-suited for handling large datasets.
- Library Support: Libraries like Apache Commons Math, Smile, and Weka simplify complex statistical computations.
- Integration: Java integrates well with big data frameworks like Hadoop and Spark, making it ideal for large-scale statistical processing.
Common Statistical Operations
Here are the key statistical metrics often used in data analysis:
- Mean (Average): The sum of all data points divided by the total number of points.
- Median: The median is the centre value in an ordered set of numbers.
- Variance: A measure of how far each number in the set is from the mean.
- Standard deviation: Is the standard deviation of variance, which represents the variation of data.
Implementing Statistical Operations in Core Java
Let’s start with a simple implementation using only Java’s core functionality.
1. Calculate Mean

2. Calculate Median

3. Calculate Variance

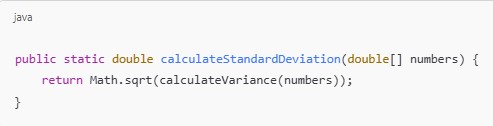
4. Calculate Standard Deviation
Using Apache Commons Math for Statistical Computations
While core Java is great for basic implementations, libraries like Apache Commons Math simplify these tasks with built-in functions.
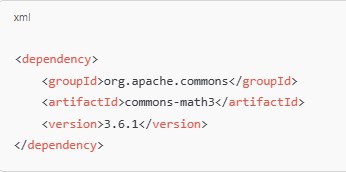
Adding Apache Commons Math Dependency
If you’re using Maven, add the following dependency to your pom.xml:
Performing Statistical Operations
Here’s how you can use Apache Commons Math to calculate basic statistics:

Key Differences: Core Java vs. Libraries
| Feature | Core Java Implementation | Apache Commons Math |
|---|---|---|
| Ease of Use | Requires manual coding of formulas | Built-in methods for computations |
| Complex Operations | Challenging for advanced metrics | Supports complex statistics |
| Readability | Less readable for large programs | Clear and concise API |
| Performance | Customizable, but less optimized | Optimized for large datasets |
Applications of Statistical Operations in Java
- Data Analysis: Calculating summary statistics for datasets.
- Machine Learning: Preprocessing data by normalizing and scaling features.
- Risk Assessment: Computing metrics like variance and standard deviation for financial data.
- Big Data Analytics: Performing statistical computations on distributed data using Java-based frameworks like Hadoop.
Tips for Efficient Statistical Computing in Java
Efficient statistical computing is crucial for handling large datasets, complex analyses, and delivering insights in a timely manner. Java, known for its performance and flexibility, offers various strategies to enhance statistical computation efficiency. Below are essential tips to improve your statistical computing workflows in Java.
1. Leverage Libraries:
While Java’s core capabilities can handle basic statistical operations, specialized libraries such as Apache Commons Math and Smile offer optimized and ready-made solutions for more advanced statistical tasks. These libraries provide pre-implemented functions for common operations like regression analysis, hypothesis testing, and probability distributions, reducing the need for custom coding and ensuring accuracy.
Benefits:
- Pre-built Functions: Libraries like Apache Commons Math and Smile offer methods for mean, median, variance, regression, and more, which can save you time on coding and debugging.
- Optimized Algorithms: These libraries are built with performance in mind and are often optimized for large datasets.
- Specialized Methods: Many Statistical Operations in Java are complex to implement manually. These libraries provide tested and reliable implementations for sophisticated tasks.
Example:
Apache Commons Math’s DescriptiveStatistics class can instantly compute key statistics like mean, variance, and Statistical Operations in Java standard deviation on large datasets with minimal code.
2. Optimize Performance:
When working with large datasets, single-threaded operations may become a bottleneck. Java provides tools like multithreading and parallel streams to execute operations concurrently, Statistical Operations in Java improving performance and reducing computation time.
Benefits:
- Concurrency: Multithreading allows different parts of a task to be performed simultaneously, leveraging multi-core processors.
- Parallel Processing: Java’s parallel streams enable data processing to be divided into smaller chunks that can be processed independently and then combined.
- Scalability: These techniques ensure that your code can scale efficiently for larger datasets without sacrificing speed.
Here, the parallel() function divides the dataset into multiple parts that can be processed concurrently, speeding up the operation.
3. Handle Edge Cases:
Real-world data is often messy and imperfect. Handling edge cases like empty datasets, missing values, or outliers is essential to prevent errors in your statistical computations and ensure the reliability of your results.
Benefits:
- Data Integrity: Addressing edge cases ensures that your Statistical Operations in Java models are robust and reliable.
- Error Prevention: Code that accounts for edge cases is less likely to fail when unexpected data is encountered.
- Resilience: Proper handling of edge cases ensures that your application can handle a variety of data inputs without crashing or producing inaccurate results.
4. Integrate Visualization:
While Statistical Operations in Java is important, visualizing the results makes the data more understandable and actionable. Java libraries like JFreeChart and JavaFX can be used to plot charts and graphs, helping to convey complex statistics visually.
Benefits:
- Enhanced Insights: Statistical Operations in Java make it easier to identify trends, patterns, and outliers in your data.
- Data Interpretation: Graphs such as histograms, bar charts, and scatter plots simplify the communication of findings to stakeholders who may not be familiar with raw statistics.
- Better Decision Making: Statistical Operations in Java can help inform decisions by clearly illustrating statistical results and highlighting key takeaways.
Final Thoughts
Java provides a versatile environment for performing Statistical Operations in Java, whether you’re using core Java methods or third-party libraries like Apache Commons Math. By mastering these techniques, you can unlock powerful insights from your data and integrate statistical analysis seamlessly into your Java applications.
Whether you’re a data scientist, software developer, or student, understanding basic statistical operations in Java is a stepping stone to more advanced analytics and data-driven decision-making. (Ref: Locus IT Services)