

Large Language Models (LLMs) have moved from research labs into boardrooms. Their potential to reshape how enterprises interact with customers, generate content, automate internal processes, and surface insights has become undeniable. Yet, excitement alone doesn’t translate into business value. Organizations experimenting with GPT-style interfaces soon realize that deploying these models into real-world environments is fraught with complexity. Compliance risks, integration challenges, model reliability, and cost management quickly surface.
It’s one thing to build a prototype using an OpenAI API—it’s another to deploy a secure, scalable, and context-aware system that handles confidential data and powers daily operations. This transition—from innovation to implementation—is where most companies stumble. And this is exactly where Locus IT brings clarity, expertise, and execution.
Why Plug-and-Play Doesn’t Scale
LLMs initially seem simple: send a prompt, get a response. Platforms like ChatGPT and Claude make it feel seamless. But as enterprises try to build around these models, major limitations emerge. Public APIs often don’t offer the flexibility or control that complex enterprise use cases demand.
Security is the first major concern. When prompts include sensitive financial, legal, or healthcare data, businesses must evaluate where that data is processed, how it is stored, and who can access it. Most API-based LLMs operate as black boxes, offering limited transparency. This creates a compliance nightmare for industries bound by HIPAA, GDPR, or ISO standards.
Next comes cost. While a few queries may seem affordable, usage-based pricing can explode unpredictably in production. Token-heavy prompts, repeated queries, and lack of caching lead to spiraling costs. Worse, there’s often no visibility into what is driving those costs until invoices arrive.
Latency and performance inconsistencies also become unacceptable at scale. What works in a demo becomes frustrating when powering a live customer support experience or internal knowledge assistant. Rate limits, throttling, and long response times cripple usability.
Lastly, generic models lack business-specific context. They can’t understand internal acronyms, products, or documentation. Their answers, while fluent, may be inaccurate or misaligned with the company’s tone, facts, or policies. Relying on a model trained on internet data will never match the value of one infused with your internal knowledge.
That’s why enterprise LLM deployment requires more than just “using an API.” It requires custom architecture, integration strategy, and governance frameworks—precisely what Locus IT delivers.
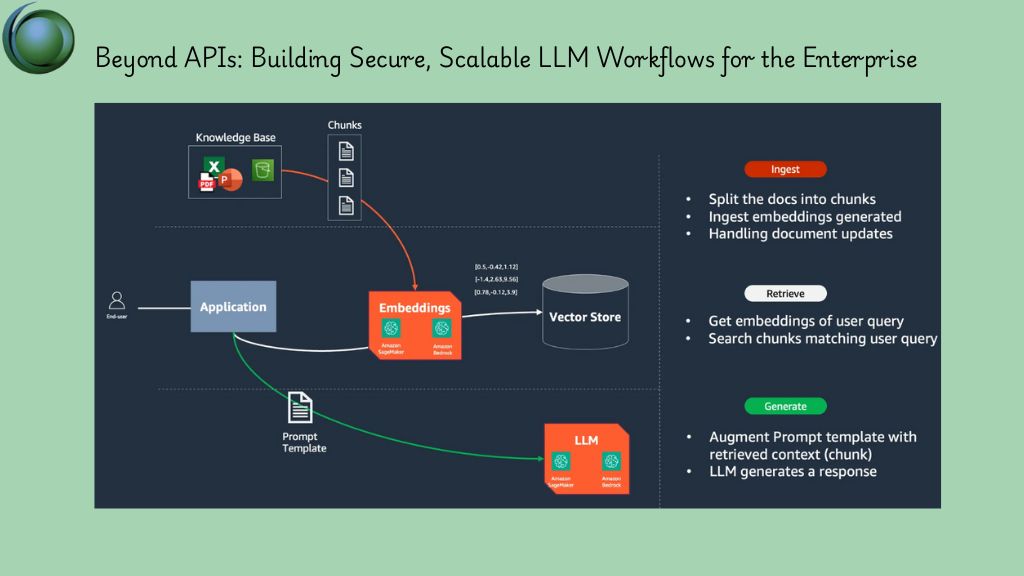
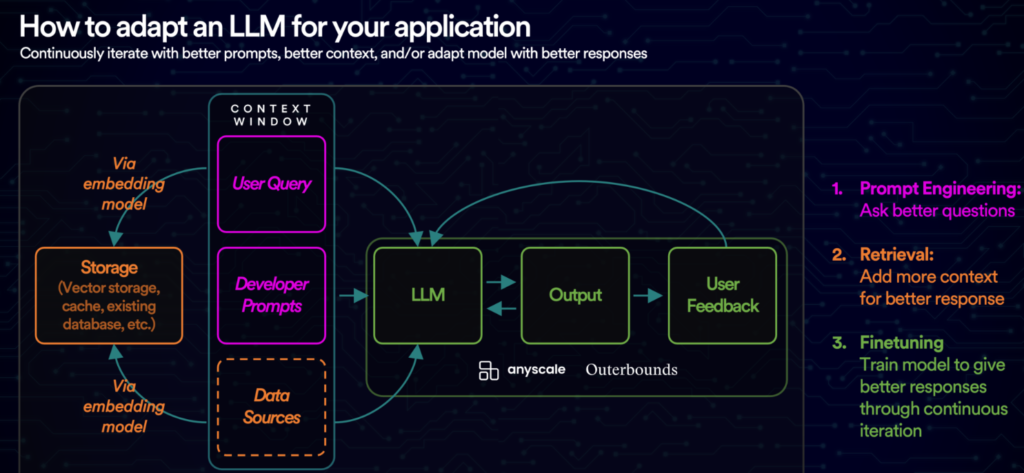
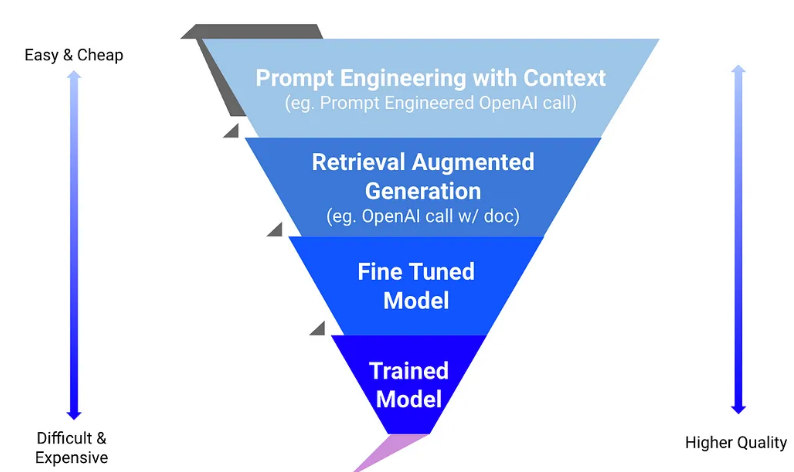
Injecting Context: Fine-Tuning and Retrieval-Augmented Generation
At the core of effective enterprise LLM deployment is the ability to make models context-aware. This can be done in two powerful ways: fine-tuning and retrieval-augmented generation (RAG).
Fine-tuning involves training an open-source LLM—such as Mistral, LLaMA, or Falcon—on your company’s specific data, such as support tickets, policy documents, technical manuals, or sales scripts. The result is a model that understands the tone, terminology, and intent of your organization. It no longer sounds like a generic assistant; it becomes an extension of your internal teams.

On the other hand, RAG offers a dynamic approach. Instead of permanently modifying a model, RAG pipelines allow models to retrieve relevant documents from a vector store (like Pinecone, FAISS, or Weaviate) at inference time. This means your LLM doesn’t need to memorize knowledge—it can “look it up” just before generating a response.
RAG is particularly valuable when your data changes often or when real-time document grounding is required. It also offers better security controls, as you can govern what documents are indexed, retrieved, and exposed in outputs.
Locus IT specializes in both strategies. We help clients select the right approach based on their data volatility, regulatory needs, and latency requirements. We build hybrid pipelines that combine embeddings, semantic search, and transformers to deliver relevant, trustworthy answers every time.
Deploying Privately: Securing the Foundation
For most enterprises, running LLMs within their own infrastructure—whether fully on-prem or in a private cloud—is essential. This ensures data sovereignty, performance control, and integration with existing IT security frameworks.
Locus IT enables secure LLM deployment using container orchestration systems like Kubernetes, and frameworks like LangChain or Haystack. We containerize open-source models and deploy them in isolated VPCs on AWS, Azure, or GCP. This enables access control, audit logging, and network-level security—all while maintaining model performance.
Locus IT Pitch: From Prototype to Production
Locus IT is not just another AI vendor—we’re your LLM integration partner. From early-stage architecture to full-scale deployment, we guide enterprises through every stage of operationalizing large language models. Book Now!

Our deployments are built for enterprise scalability. We leverage GPU-backed autoscaling for inference, optimize serving stacks with tools like vLLM and Triton Inference Server, and integrate observability tools for performance tuning.
Role-based access control (RBAC) ensures that only authorized teams can use specific models or see sensitive outputs. We also implement redaction filters, encryption-in-transit, and dynamic prompt governance to ensure full compliance with organizational policies.
These aren’t optional extras—they are critical foundations for enterprise LLM deployment.
From Model to Business Workflow: Connecting the Dots
An LLM that lives in isolation won’t generate ROI. The real value comes when it is embedded in business workflows. Whether it’s surfacing in customer-facing apps, employee portals, or operational dashboards, LLMs must be deeply integrated to drive impact.
Locus IT builds end-to-end solutions that embed LLMs into:
- Customer service systems to draft replies, summarize tickets, and suggest resolutions.
- CRM platforms like Salesforce to generate follow-up emails, summarize opportunities, and interpret notes.
- HR systems to answer policy queries, auto-generate onboarding guides, and assist with compliance FAQs.
- Knowledge management tools that allow employees to chat with internal documentation.
We develop APIs, webhooks, and middleware that seamlessly connect the LLM’s outputs to your existing tools. More importantly, we enable real-time feedback loops where user corrections improve future results—turning a static model into a continuously learning assistant.
Governance: The Silent Backbone of Enterprise AI
LLM deployment can quietly fall apart without governance. When different teams use different prompts, models, and access methods, chaos ensues. Data lineage disappears, trust in outputs erodes, and auditability vanishes.
Locus IT brings order to this complexity. We implement centralized prompt registries, version control for model updates, and permission structures that mirror your org hierarchy. Our workflows ensure that models are traceable, outputs are explainable, and decisions can be audited.
We also embed enterprise-grade monitoring. Every token used, prompt served, and document retrieved is logged. We integrate these logs with SIEM and APM tools to ensure that your LLM infrastructure meets the same reliability standards as any core IT system.
Through tools like MLflow, Databricks Model Registry, and our own dashboards, we help your teams control experimentation while preparing models for stable deployment.
Optimizing for Cost and Performance
One of the most underestimated aspects of enterprise LLM deployment is cost management. Without token budgeting, intelligent caching, and usage analytics, expenses can balloon rapidly.
Locus IT implements strategies like:
- Query caching for repeated prompts and static outputs
- Model routing where simpler prompts are sent to lightweight models
- Token trimming to shorten inputs intelligently
- Usage-based throttling and billing dashboards for cost transparency
We also optimize performance using quantized models (e.g., using GGUF or INT4 formats), low-rank adaptation (LoRA), and lazy-loading of large models. This ensures that even massive models can be served with minimal compute waste.
The Locus IT Advantage: LLM Systems That Deliver
Our team brings:
- Expertise in open-source models (Mistral, Falcon, LLaMA, Gemma)
- Experience across cloud ecosystems (AWS, Azure, GCP)
- Deep knowledge of MLOps workflows (Databricks, MLflow, Airflow)
- Proven success in real-world integrations (Salesforce, ServiceNow, Confluence, Jira)
- A focus on security, compliance, and performance
We don’t just build chatbots—we engineer intelligent systems that augment your teams, accelerate your workflows, and unlock AI-powered transformation at scale.
Conclusion: It’s Time to Operationalize LLMs

The age of AI demos is over. What businesses need now are deployable, governable, and high-impact LLM solutions. Success depends on the right mix of technical architecture, security protocols, domain adaptation, and performance engineering.
Locus IT helps enterprises move from pilot projects to production deployments—transforming LLMs from experiments into strategic business assets. If your organization is ready to go beyond API calls and invest in enterprise LLM deployment, we’re ready to partner with you.
Let’s build something intelligent. Let’s build something real.
Reference : https://en.wikipedia.org/wiki/Large_language_model