

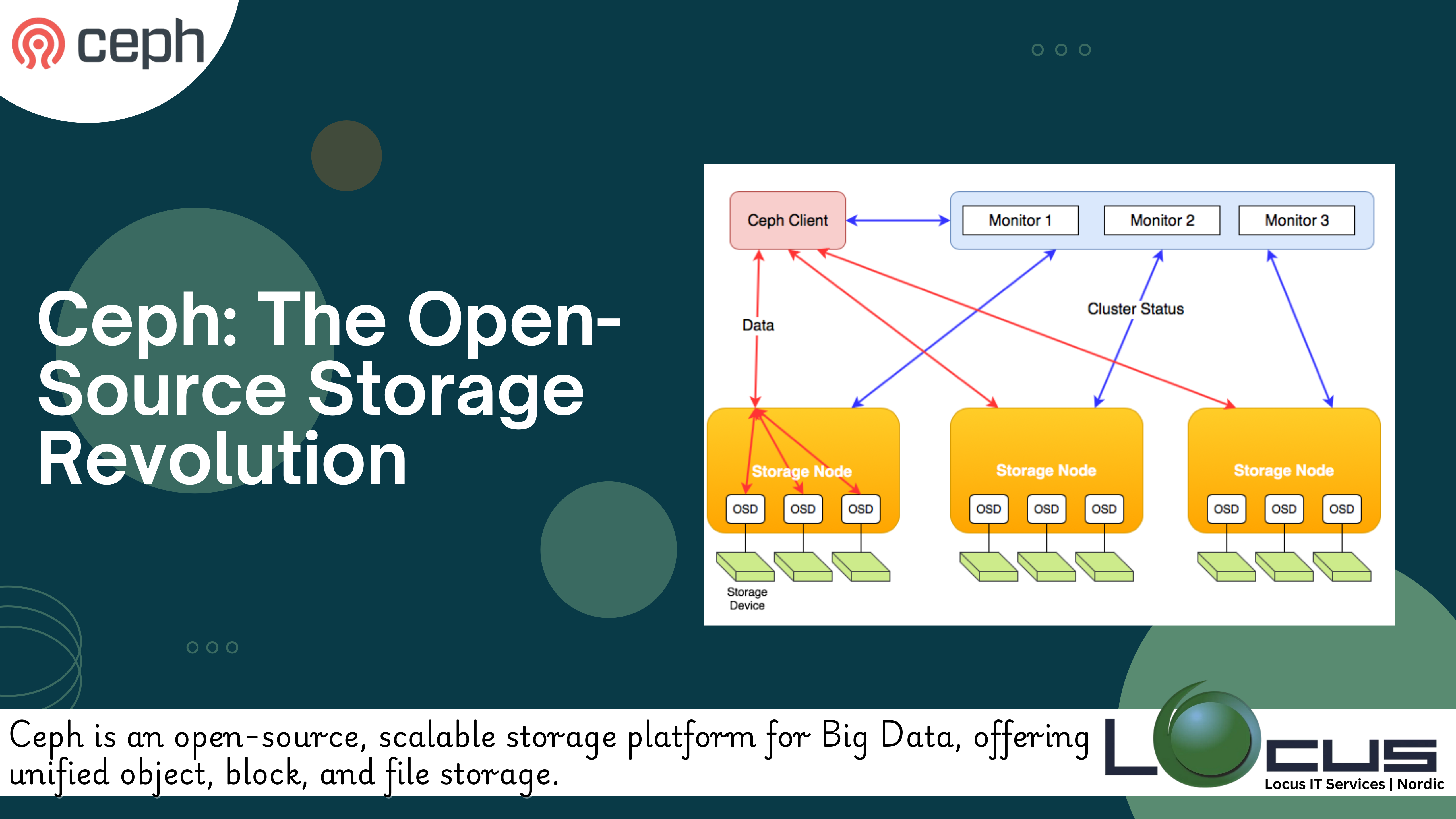
Ceph is an open-source software-defined storage platform that provides unified, scalable, and reliable storage for Big Data and cloud environments. Ceph is designed to deliver object, block, and file storage in a single, unified system, making it a versatile solution for various storage needs in large-scale data environments. It is particularly popular in Big Data ecosystems where high availability, scalability, and fault tolerance are critical. Here’s an overview of Ceph and its relevance in Big Data:
Table of Contents
Key Features of Ceph in Big Data:

- Unified Storage System:
- Object Storage (RADOS): It’s core is the Reliable Autonomic Distributed Object Store (RADOS), which provides highly scalable object storage. This is ideal for storing unstructured data, such as multimedia files, backups, and large datasets typically found in Big Data applications.
- Block Storage (RBD): Provides block storage through its RADOS Block Device (RBD), which is often used for virtual machine images, databases, and applications requiring high-performance storage.
- File System (CephFS): It also offers a POSIX-compliant distributed file system called CephFS. This allows applications to interact with Ceph storage as if it were a traditional file system, making it easier to integrate with existing applications.
- Scalability:
- Horizontal Scaling: Is designed to scale horizontally by adding more storage nodes to the cluster. It can scale from a few nodes to thousands, handling petabytes of data across distributed systems. This scalability is crucial in Big Data environments where data volumes can grow rapidly.
- Dynamic Scaling: Supports dynamic scaling, meaning that storage capacity can be expanded by simply adding more nodes without interrupting the service. This flexibility is essential for environments where storage demands are unpredictable.
- Fault Tolerance and High Availability:
- Data Replication and Erasure Coding: Provides data protection through replication and erasure coding. Replication ensures that multiple copies of data are stored across different nodes, while erasure coding provides efficient data redundancy with less storage overhead. These features ensure high availability and data durability, even in the case of hardware failures.
- Self-Healing: Automatically detects and repairs data inconsistencies. If a storage node fails, Ceph rebalances the data across the remaining nodes to maintain the desired level of redundancy and availability.
- Distributed Architecture:
- No Single Point of Failure: It’s architecture is fully distributed, with no single point of failure. All components of the Ceph cluster (monitors, OSDs, and managers) are distributed across multiple nodes, ensuring continuous availability and resilience against failures.
- CRUSH Algorithm: It’s uses the CRUSH (Controlled Replication Under Scalable Hashing) algorithm to determine how data is distributed and replicated across the cluster. CRUSH ensures even data distribution and efficient resource utilization, which is critical in large-scale Big Data environments.
- Compatibility and Integration:
- OpenStack Integration: Is widely used as the storage backend for OpenStack, a popular open-source cloud computing platform. This integration makes it easy to deploy scalable cloud storage solutions that support Big Data workloads.
- Hadoop and Spark Integration: It can be integrated with Hadoop and Apache Spark, enabling Big Data analytics workloads to leverage Ceph’s scalable and resilient storage infrastructure. This integration allows for more flexible and efficient data processing pipelines.
- Performance Optimization:
- Adaptive Caching: Includes various caching mechanisms to optimize read and write performance, such as write-back and write-through caches. These features improve the performance of Big Data applications that require fast access to large datasets.
- Load Balancing: Automatically balances the workload across the storage cluster to prevent any single node from becoming a bottleneck. This load balancing is essential in Big Data environments where high throughput and low latency are required.
- Data Management and Monitoring:
- Ceph Dashboard: Provides a built-in management and monitoring dashboard that offers real-time insights into the health, performance, and utilization of the storage cluster. This is particularly useful for managing large-scale Big Data storage environments.
- Automated Tiering: Supports automated data tiering, which moves data between different storage tiers based on usage patterns. This helps optimize storage costs and performance by ensuring that frequently accessed data resides on faster storage.
- Security:
- Data Encryption: Supports encryption of data at rest and in transit, ensuring that sensitive information is protected against unauthorized access. This is critical for Big Data applications that handle sensitive or regulated data.
- Role-Based Access Control (RBAC): Includes role-based access control to manage permissions and ensure that only authorized users can access specific data or perform certain operations.
Use Cases of Ceph in Big Data:

- Data Lakes: It’s object storage capabilities make it an ideal solution for building data lakes, where vast amounts of unstructured and semi-structured data can be stored, processed, and analyzed. Ceph’s scalability ensures that the data lake can grow as needed.
- Backup and Archiving: It’s fault tolerance and high availability make it a reliable choice for backup and archiving solutions in Big Data environments, ensuring that critical data is always protected and accessible.
- Cloud Storage for Big Data: Is commonly used as the storage backend for cloud platforms that support Big Data workloads, such as OpenStack. This enables organizations to build scalable, private cloud storage solutions that can handle the demands of Big Data applications.
- High-Performance Computing (HPC): It’s ability to deliver high-throughput, low-latency storage makes it suitable for high-performance computing applications that require fast access to large datasets, such as scientific simulations and data analytics.
Advantages of Ceph in Big Data:
- Unified Storage Platform: It provides object, block, and file storage in a single platform, simplifying storage management and reducing the need for multiple storage solutions in Big Data environments.
- Scalability: It’s ability to scale horizontally without downtime makes it ideal for Big Data environments where data volumes can grow rapidly and unpredictably.
- High Availability and Fault Tolerance: Ceph’s data replication, erasure coding, and self-healing features ensure that data is always available, even in the event of hardware failures, which is crucial for maintaining the integrity of Big Data applications.
- Open-Source Flexibility: As an open-source solution, Ceph can be customized to meet specific needs, and it benefits from a large community of developers and users who contribute to its ongoing development and improvement.
Challenges:
- Complexity in Deployment and Management: Setting up and managing a Ceph cluster can be complex, particularly in large-scale environments. It requires a good understanding of Ceph’s architecture and careful planning to ensure optimal performance and reliability.
- Resource Intensive: Ceph can be resource-intensive, requiring significant computational, memory, and storage resources, especially when scaling to handle large Big Data workloads.
- Performance Tuning: Achieving optimal performance with Ceph in a Big Data environment may require careful tuning of the storage cluster, including configuring the CRUSH map, caching settings, and network optimizations.
Comparison to Other Storage Solutions:
- Ceph vs. HDFS: Hadoop Distributed File System (HDFS) is a widely used storage system in Big Data environments. While HDFS is optimized for large-scale data processing with Hadoop, Ceph offers a more versatile storage solution that supports object, block, and file storage. Ceph also provides better fault tolerance and data protection features compared to HDFS. (Ref: Hadoop Distributed File System HDFS for Data Science)
- Ceph vs. GlusterFS: GlusterFS is another open-source distributed file system. While both Ceph and GlusterFS are used in scalable storage environments, Ceph is often preferred for its more advanced features, such as erasure coding, dynamic load balancing, and unified storage capabilities.
- Ceph vs. AWS S3: AWS S3 is a cloud-based object storage service. While S3 is highly scalable and widely used in cloud environments, Ceph offers a self-hosted alternative that provides similar object storage capabilities, with the added benefit of supporting block and file storage in the same cluster.
Ceph is a powerful, scalable, and reliable storage platform that is well-suited for Big Data environments. Its ability to provide unified object, block, and file storage, combined with its fault tolerance, high availability, and scalability, makes it an ideal choice for organizations looking to build and manage large-scale data storage solutions. Whether used for data lakes, backup and archiving, or high-performance computing, Ceph offers the flexibility and robustness needed to support the demanding storage requirements of Big Data applications.