

For Every Business, data is one of the most valuable assets for businesses. From customer insights and operational efficiency to predictive analytics and machine learning, organizations across industries are leveraging Big Data to make smarter, more informed decisions. However, efficiently processing and analyzing vast volumes of structured and unstructured data requires a solid Big Data architecture.
In this blog post, we’ll explore the essentials of Big Data architecture, discuss key components, and examine how a well-designed architecture can support various data-driven applications.
Table of Contents
What is Big Data Architecture?
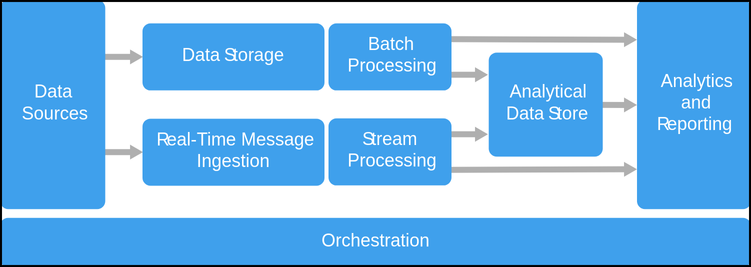
Big Data architecture is a framework that defines how to collect, store, process, and analyze large amounts of data. It ensures that data flows seamlessly from ingestion to storage, processing, and output, supporting applications that can turn raw data into actionable insights. This architecture is designed to handle the 3Vs of Big Data: Volume (scale), Velocity (speed), and Variety (diverse data types).
Whether it’s real-time analytics, batch processing, or a hybrid of both, Big Data architecture provides the backbone for data-driven applications, enabling businesses to gain insights and make decisions quickly and efficiently.
Key Components of Big Data Architecture
- Data Sources
Big Data architecture starts with data sources, which can come from various streams:- 1. Structured data from databases, CRM systems, or ERP applications.
- 2. Unstructured data such as emails, documents, social media posts, and multimedia files.
- 3. Real-time data from IoT sensors, logs, or clickstream data.
- Data Ingestion Layer
The ingestion layer is responsible for gathering and importing data from diverse sources into the architecture. It enables data to be streamed in real-time or ingested in batches.- 1. Batch Ingestion: Processes large volumes of data at intervals. Useful for historical data analysis.
- 2. Real-Time Streaming: Ingests and processes data as it arrives. Tools like Apache Kafka, Flume, and Amazon Kinesis are popular choices for streaming data.
- Data Storage Layer
A critical component, the storage layer, holds data until it’s ready for analysis. Depending on the data type and business needs, storage solutions can vary:- Data Lakes: Store raw, unprocessed data in its native format, providing flexibility for large datasets.
- Data Warehouses: Store structured data in a highly organized, query-optimized format.
- Hybrid Storage: Many architectures combine data lakes and warehouses, creating a data lakehouse to store both structured and unstructured data.
- Data Processing Layer
This layer is responsible for cleaning, transforming, and analyzing data. Processing can happen in:- Batch Processing: Tools like Apache Spark and Hadoop MapReduce process data in bulk, useful for large volumes of historical data.Real-Time Processing: Tools like Apache Storm, Apache Flink, and Spark Streaming handle data as it arrives, ideal for real-time analytics.
- Data Analytics Layer
The analytics layer runs advanced analyses, from basic reporting to machine learning, to uncover insights. This layer supports: (Ref: Advanced Data Analytics & Insights: Unlocking the Power of Big Data)- Descriptive Analytics: Summarizes historical data to understand what happened.
- Predictive Analytics: Uses models to predict future outcomes.
- Prescriptive Analytics: Recommends actions based on predictions.
- Data Access and Consumption Layer
This layer enables users and applications to interact with and consume insights from the architecture.- 1. Business Intelligence Tools: Allow users to create dashboards and reports.
- 2. APIs and Applications: Support programmatic access to data and analytical insights.
- Security and Compliance Layer
Protecting sensitive data and ensuring compliance with regulations (like GDPR and HIPAA) is essential in Big Data architecture. This layer includes:- 1. Data Encryption: Protects data at rest and in transit.
- 2. Access Control: Ensures only authorized users can access sensitive data.
- 3. Monitoring and Auditing: Tracks data access and changes for accountability.
Types of Big Data Architecture
- Lambda Architecture
Lambda architecture combines both batch and real-time data processing to create a robust, scalable system.- Batch Layer: Processes historical data to provide accurate, long-term storage and batch processing.
- Speed Layer: Handles real-time data to provide immediate insights.
- Serving Layer: Combines batch and real-time data for comprehensive analytics.
- Kappa Architecture
Unlike Lambda, Kappa architecture relies solely on real-time streaming and processing, bypassing batch processing. This approach is well-suited for use cases that require immediate insights without the need for historical data. Kappa architecture works well for applications like real-time monitoring and predictive maintenance, where real-time processing is essential, and historical accuracy is less critical. - Modern Data Lakehouse
Data Lake Houses combine the best of data lakes and warehouses, offering scalability and flexibility while ensuring data is structured and query-ready. This architecture is beneficial for companies needing to manage both structured and unstructured data in a unified platform, allowing for flexible, cost-effective data processing.
Benefits of Big Data Architecture
- Scalability
Big Data architecture allows companies to scale storage and processing power to handle massive data volumes. Cloud-based solutions like AWS, Azure, and Google Cloud offer easy scalability, enabling organizations to adjust resources based on demand. - Real-Time Insights
With a mix of batch and streaming processing, Big Data architectures enable companies to obtain real-time insights, supporting time-sensitive applications like fraud detection, customer sentiment analysis, and personalized recommendations. - Cost-Efficiency
By incorporating cloud services, Big Data architectures help reduce the costs associated with on-premise storage and processing. Data lakes also provide cost-effective storage for vast amounts of raw data, which can be processed as needed. - Enhanced Decision-Making
Big Data architectures allow businesses to analyze data from multiple sources and gain a more comprehensive view of their operations. From predictive analytics to personalized customer experiences, data-driven decision-making improves competitiveness and customer satisfaction.
Key Considerations When Designing Big Data Architecture

- Data Governance and Compliance
Establish policies and procedures to manage data quality, integrity, and security. A robust governance strategy ensures data remains trustworthy and compliant with legal standards. - Data Integration
Integrate data from multiple sources, ensuring seamless compatibility across formats. Tools like Apache NiFi, Informatica, and Talend are useful for this purpose. - Latency Requirements
Understand the latency needs of different applications. For some cases, batch processing suffices, while others require real-time data streaming for instant insights. - Data Storage Optimization
Use the appropriate storage solution based on the type of data and the processing requirements. Structured data often fits well in warehouses, while raw and semi-structured data can be stored cost-effectively in data lakes. - Future Scalability
Design the architecture to accommodate future data growth and evolving business needs. Consider using cloud-based solutions, which offer scalable storage and processing power, making it easier to handle larger volumes and new types of data.
Final Thoughts: Building for a Data-Driven Future
Big Data architecture is the backbone of modern data-driven applications, enabling organizations to transform vast amounts of data into actionable insights. With an effective architecture, companies can gain a competitive edge, improve customer experiences, and drive innovation.
As organizations continue to embrace data-driven decision-making, the importance of robust, flexible, and scalable Big Data architectures will only grow. Whether through cloud-based solutions or hybrid environments, building the right architecture today ensures a stronger, data-powered tomorrow.