

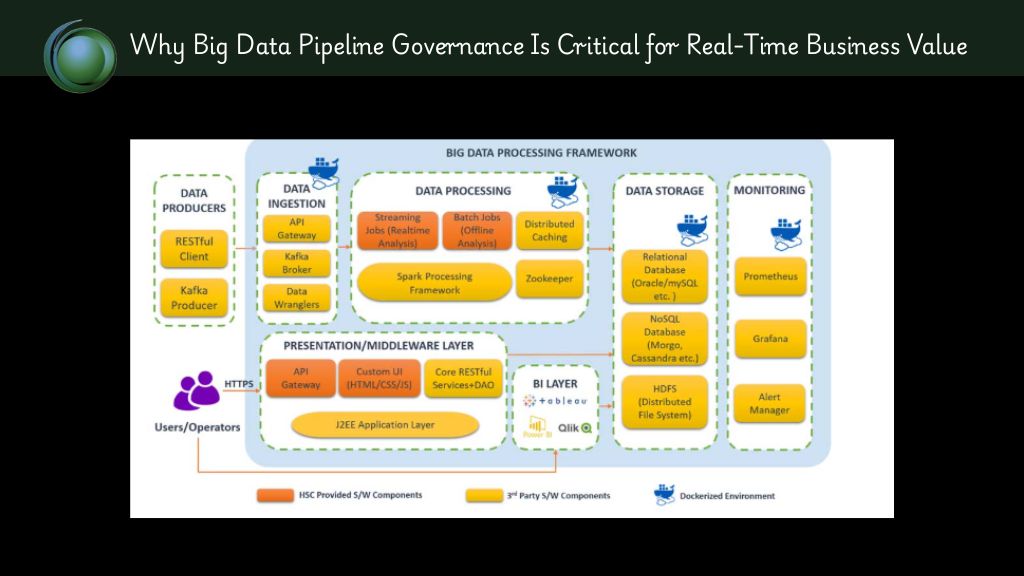
The promise of Big Data pipelines was revolutionary where we gain insights at scale, predict trends before they emerge and transform decision-making across the enterprise. But the reality has often been messier. Enterprises that once rushed to accumulate petabytes of data now find themselves facing a different kind of challenge: the inability to govern, scale, or derive timely value from their Big Data systems.
The result is data chaos. Reductant data pipelines, delayed insights, quality issues, and compliance gaps are common in ecosystems where governance wasn’t prioritized from the start. Scaling makes it worse. As data velocity, variety, and volume increase, technical debt accumulates faster than innovation.
This is where robust Big Data pipeline governance becomes essential as a foundation for scalable business value.
What Makes Big Data Pipelines Fragile?
At their core, Big Data pipelines involve ingestion, transformation, storage, and delivery of data across a distributed architecture. But many pipelines today are brittle for a few reasons.
First, the variety of data sources—from clickstreams and IoT sensors to CRM platforms and external APIs—means ingestion logic is often ad hoc. Each source may require custom parsing, schema handling, and transformation.
Second, pipelines lack visibility. With dozens of ETL or ELT jobs running across Spark clusters, Airflow DAGs, Kafka topics, or Snowflake tasks, it’s difficult to trace data lineage, monitor failures, or ensure consistency across environments.
About Locus IT Services in Big Data Pipelines
Locus IT is a pioneer in data engineering and analytics consulting with a strong focus on Big Data pipelines, cloud-native architectures, and real-time analytics. With expertise across AWS, Azure, and GCP, and platforms like Databricks, Kafka, Snowflake, and Airflow, Locus IT helps clients move from Big Data ambition to operational excellence. From advisory to implementation and managed services, our team ensures your data works as hard as you do.. Book Now!

Governance: The Missing Link Between Chaos and Value
Governance isn’t just about control or compliance—it’s about creating an infrastructure where Big Data can be trusted, reused, and scaled. Governance frameworks ensure that data:
- Comes from known, auditable sources
- Is transformed using transparent logic
- Is accessed with appropriate permissions
- Can be traced back to its origin
- Meets business SLAs for freshness and quality
When implemented well, governance increases team productivity, reduces debugging time, improves model accuracy, and shortens time-to-insight.
Locus IT has helped several enterprises embed governance frameworks into their data engineering practices. By designing governance alongside technical pipelines—not as an afterthought—our clients achieve both speed and reliability at scale.
The Architecture of a Governed, Scalable Pipeline
Let’s break down a reference architecture for a modern, governed Big Data pipeline—something Locus IT often implements across industries.
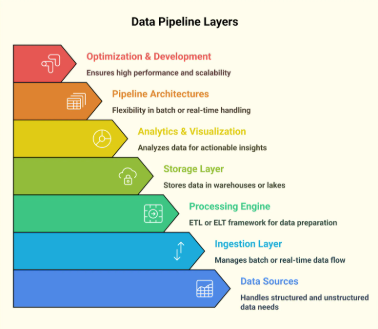
- Ingestion Layer: Data from streaming and batch sources is ingested using tools like Apache Kafka, AWS Glue, or Azure Data Factory. Here, schema contracts and data validation are applied at the edge.
- Processing Layer: Apache Spark (batch) and Structured Streaming (real-time) handle transformations, enriched with metadata tracking and unit tests. Locus IT integrates these with orchestration tools like Airflow or Azure Data Factory pipelines.
- Storage Layer: Delta Lake, Apache Iceberg, or Hudi provide versioned, ACID-compliant storage—key for time travel, rollback, and safe schema evolution.
- Metadata and Governance: Tools like Apache Atlas, Amundsen, or commercial catalogs (e.g., AWS Glue Data Catalog, Azure Purview) offer data lineage, ownership, and classification tags.
- Access Layer: Data is exposed to BI tools, ML pipelines, or APIs, controlled via Role-Based Access Control (RBAC) and policy-based governance integrated with IAM systems.
- Monitoring & Alerting: Quality checks, latency SLAs, and pipeline health metrics are monitored using tools like Great Expectations, Prometheus, or custom dashboards.
Locus IT specializes in deploying this reference architecture across AWS, Azure, and GCP, tailoring it to the client’s data maturity and compliance needs.
Real-Time + Batch: Solving for Hybrid Use Cases
Enterprises rarely operate in a purely batch or purely real-time world. Fraud detection, logistics tracking, user behavior analytics—all demand hybrid pipelines. But combining real-time Kafka streams with batch-processed Parquet datasets introduces architectural and governance complexity.
Locus IT helps bridge these systems with data lakehouse solutions and stream-to-batch unification strategies. For example, Databricks Delta Live Tables allow structured streaming to write to Delta Lake while maintaining a unified schema—greatly simplifying downstream BI and ML.
By using consistent transformation logic across batch and real-time, we help clients minimize code duplication, enforce governance across layers, and support diverse SLAs.
Data Quality: The Costliest Governance Blind Spot
One of the most common complaints from data consumers is “I don’t trust this dashboard.” That lack of trust stems from inconsistent definitions, broken joins, stale records, or missing values.
Governance must address this head-on through data quality monitoring, versioning, and alerting. At Locus IT, we implement automated data testing suites (using Great Expectations or custom Spark test frameworks) that validate assumptions at every Big Data pipelines stage.
These tests are versioned, logged, and integrated into CI/CD pipelines. So, just like application code, data logic is tested before release.
The People Side: Roles, Ownership, and Collaboration
Technology isn’t enough. Big Data pipelines governance requires clear roles:
- Data Owners define quality metrics and approval processes
- Data Stewards monitor and improve metadata completeness
- Engineers build pipelines with built-in governance hooks
- Analysts and Scientists trust that data is reliable and documented
Locus IT facilitates this collaboration with training, playbooks, and metadata-driven UIs that make governance accessible to non-engineers. By embedding ownership into daily workflows, governance becomes self-reinforcing.
Cloud-Native Governance: More Than Tools
Public clouds offer powerful tools for Big Data pipelines—AWS Lake Formation, Azure Purview, Google Dataplex. But these are not plug-and-play solutions.
You need a governance strategy, not just a stack. For instance, should data contracts be embedded at ingestion or enforced downstream? Should RBAC be centralized or delegated to teams? How do you evolve schemas without breaking Looker dashboards?
Locus IT Pitch: Accelerating Your Big Data Pipelines Governance
Locus IT has helped global clients navigate these choices across regulated sectors like finance and healthcare. Our governance blueprints consider regulatory requirements (like HIPAA, GDPR), business needs (like SLA commitments), and platform capabilities—then align them into a cohesive data ops strategy.
Locus IT in Action: Case Snapshots
A Retail Giant’s Freshness Problem
A large omnichannel retailer was facing delays of up to 12 hours before sales data was available in dashboards. After assessing their data lake ingestion and ELT patterns, Locus IT redesigned their pipelines with Spark Structured Streaming and Databricks Delta Live Tables. We added freshness SLAs and automatic alerts, cutting the delay to under 15 minutes and restoring stakeholder confidence.
A Fintech Firm’s Compliance Headache
A fintech company had multiple Snowflake accounts and no centralized view of who had access to what data. Locus IT implemented metadata catalogs and lineage tools across environments and built audit-ready dashboards for access and transformation history. The result: clean GDPR audit trails and smoother internal approvals.
A Manufacturing Leader’s ML Stagnation
A manufacturer’s ML team was struggling with inconsistent training data from batch systems. We created a data mesh approach with governed feature stores on Databricks, ensuring that ML and BI teams used the same canonical data sources. Model accuracy improved, and time-to-production was halved.
The Future: Autonomic Data Pipelines
Governed Big Data pipelines are evolving. The next frontier is autonomic data systems—pipelines that self-monitor, self-heal, and adapt to schema or logic changes in real time.
Locus IT is actively researching and building toward this vision. Our teams integrate ML into data pipelines themselves—detecting anomalies, recommending transformations, or triggering escalations. With cloud-native infrastructure and serverless data orchestration, the dream of autonomous pipelines is becoming real.
Final Thoughts: Build Once, Scale Forever
Enterprises can’t afford to “move fast and break data” anymore. The cost of broken trust—whether with customers, regulators, or internal stakeholders—is too high.

Instead, the winning strategy is: move fast, but govern as you go. Build Big Data pipelines with lineage, versioning, and access control from day one. Make governance a business enabler, not a bottleneck.
Locus IT’s deep experience in cloud data platforms, modern data stack integration, and governance best practices makes us the right partner for organizations that want to scale Big Data pipelines without chaos. Whether you’re just starting with a data lake or modernizing legacy Hadoop infrastructure, we can help you design for trust, agility, and real-time value.
References : https://en.wikipedia.org/wiki/Big_data