


For Every Business, The field of genomics is rapidly evolving, generating massive amounts of data that require advanced tools and techniques for analysis. Genomic Data Analysis in R involves exploring and interpreting DNA, RNA, and protein data to understand biological processes, identify genetic markers, and advance fields like personalized medicine. R, with its extensive ecosystem of packages tailored for bioinformatics, is a popular choice for genomic data analysis.
However, the sheer size and complexity of genomic datasets, often reaching terabytes, pose challenges for efficient analysis. Optimizing genomic data analysis workflows in R is essential to manage large-scale data efficiently, reduce computation time, and extract meaningful insights. In this blog post, we explore strategies and best practices for optimizing genomic data analysis in R. (Ref: Real-World Examples Using Tidyverse Functions in R)
Challenges in Genomic Data Analysis in R

- Data Volume: Genomic datasets are enormous, making storage, preprocessing, and analysis computationally intensive.
- High Dimensionality: Genomic data often involve thousands of features (genes or variants) and millions of samples.
- Complex Pipelines: Workflows can include multiple steps like alignment, annotation, normalization, and statistical analysis.
- Computational Bottlenecks: Limited memory and processing power can slow down analyses, especially with large datasets.
Optimizing Genomic Data Analysis in R
To address these challenges, it’s essential to adopt optimization techniques that improve computational performance and streamline workflows.
1. Leverage Specialized Packages for Genomics
R offers a rich ecosystem of packages designed specifically for genomic data analysis. Using these optimized tools can significantly enhance performance.
- Bioconductor: Bioconductor is the go-to repository for genomic analysis in R, offering packages for tasks like sequence alignment, differential expression analysis, and annotation.
- Example packages:
GenomicRanges: Efficient handling of genomic intervals and ranges.DESeq2: Differential gene expression analysis.edgeR: RNA-Seq data analysis.Biostrings: Manipulation of biological sequences.
- Example packages:
- VariantAnnotation: For analyzing and annotating Variant Call Format (VCF) files.
These packages are optimized for genomic workflows and provide tools tailored for large-scale data.
2. Optimize Data Structures
Efficient data structures can significantly reduce memory usage and improve processing speeds.
- SummarizedExperiment: Use the
SummarizedExperimentclass for managing genomic datasets. It combines assay data (e.g., expression values) with metadata (e.g., sample annotations) in a single object, making it easier to handle complex data. - Data Tables: Use the
data.tablepackage for large tabular data. It is faster and more memory-efficient than standard data frames. - Sparse Matrices: For datasets with many zeros (e.g., gene expression matrices), use sparse matrices from the
Matrixpackage to save memory and speed up computations.
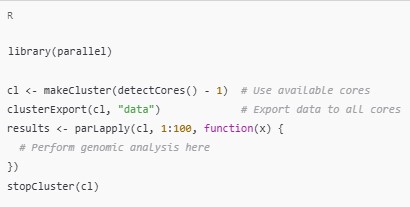
3. Parallel Computing for Performance Gains
Genomic data analysis often involves computationally expensive tasks that can benefit from parallel processing.
- Multithreading: Many Bioconductor packages support multithreading for tasks like alignment and normalization. Use functions like
bplapplyfrom theBiocParallelpackage to parallelize workflows. - Parallel Packages: Leverage R’s parallel computing capabilities with packages like
parallel,foreach, anddoParallelto speed up loops and repetitive tasks.
Example:
4. Use Cloud-Based Solutions
Cloud computing provides scalable resources for genomic analysis, enabling the processing of large datasets without hardware limitations.
- RStudio on Cloud Platforms: Deploy RStudio on AWS, Azure, or Google Cloud for high-performance analysis.
- Big Data Tools Integration: Use packages like sparklyr to integrate R with Apache Spark for distributed computing, ideal for massive genomic datasets.
5. Efficient File Handling and Storage
Genomic datasets often come in specialized file formats like FASTQ, BAM, and VCF. Efficient handling of these files is critical for performance.
- Indexed Files: Use indexed file formats (e.g., BAM with .bai index files) to enable quick access to specific regions of the genome without loading the entire file.
- Compression: Store data in compressed formats like BGZF to reduce disk usage and speed up file I/O operations.
- Efficient Parsing: Use Bioconductor packages like
Rsamtoolsfor reading BAM files andVariantAnnotationfor VCF files.
6. Statistical Analysis and Machine Learning
Optimizing statistical and machine learning workflows can improve the speed and accuracy of Genomic Data Analysis in R.
- Feature Selection: Reduce dimensionality by selecting the most relevant genes or variants. This speeds up downstream analysis and improves model performance.
- Efficient Algorithms: Use optimized machine learning libraries like
caret,mlr3, ortidymodelsfor predictive modeling. - Sampling Techniques: For very large datasets, Genomic Data Analysis in R consider random sampling or stratified sampling to reduce computational overhead during exploratory analysis.
7. Automation and Workflow Management
Automating genomic analysis pipelines ensures reproducibility and saves time.
- Workflow Packages: Use tools like
drakeortargetsto build and manage genomic workflows. These packages automatically rerun steps only when inputs change. - Snakemake Integration: For more complex pipelines, integrate R with workflow management systems like Snakemake to handle dependencies and parallel execution.
8. Visualization of Genomic Data
Effective visualization is critical for interpreting Genomic Data Analysis in R. Optimize visualizations to handle large datasets.
- ggplot2: Use the
ggplot2package for creating publication-ready visualizations. Optimize performance with theggforceorggraphpackages for complex genomic plots. - Genome Browsers: Visualize genomic intervals using tools like
GvizorIGV(Integrated Genome Viewer).
Final Thoughts
Optimizing genomic data analysis in R requires a combination of efficient data handling, parallel computing, specialized tools, and automation. By leveraging R’s robust ecosystem of bioinformatics packages and adopting strategies for high-performance computing, Genomic Data Analysis in R researchers can process large-scale genomic datasets efficiently, extract meaningful insights, and accelerate discoveries.
Whether you’re analyzing gene expression data, Genomic Data Analysis in R identifying genetic variants, or modeling complex interactions, these optimization techniques will help you harness the full potential of R for genomic research. (Ref: Locus IT Services)