


Data pipelines are the backbone of modern data architectures, enabling seamless data integration, transformation, and delivery. With the growing demand for scalable, efficient, and cost-effective data workflows, Snowflake has emerged as a powerful platform to build and optimize data pipelines. Whether you’re handling batch processing, real-time data ingestion, or complex data transformations, Snowflake offers a versatile and robust environment for building scalable data pipelines.
In this blog post, we will explore best practices and techniques for designing data pipelines in Snowflake to ensure efficient, reliable, and scalable data workflows.
To learn more or schedule a consultation, connect with us today and discover how we can support your data analytics journey.
Why Design Data Pipelines in Snowflake?
Snowflake provides a fully-managed cloud data platform that is optimized for speed, scalability, and cost efficiency. Its architecture allows organizations to separate compute and storage, enabling elastic scalability. Additionally, Snowflake’s support for semi-structured data, powerful SQL capabilities, and seamless integrations with third-party tools make it an ideal choice for Designing Data Pipelines. (Ref: Snowflake Advanced Security Features: Protecting Your Data in the Cloud)
Key Benefits of Using Snowflake for Designing Data Pipelines:
- Scalability: Automatically scale compute resources to meet workload demands.
- Flexibility: Handle both structured and semi-structured data (JSON, Avro, Parquet).
- Performance: Leverage query optimization techniques like result caching and clustering.
- Security: Strong access control, data encryption, and compliance features.
- Integration: Connect easily with cloud storage, ETL tools, and BI platforms.
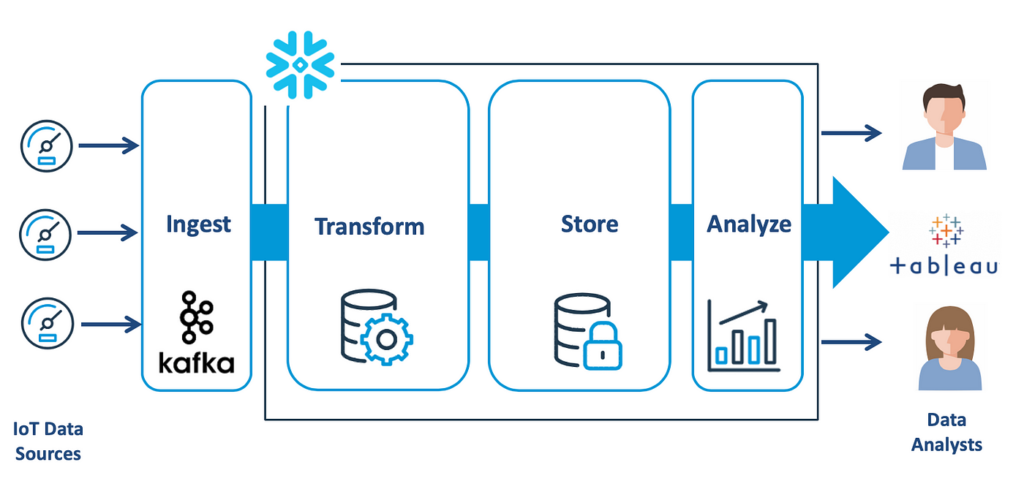
Step 1: Understand the Data Flow in Snowflake
When Designing Data Pipelines in Snowflake, the first step is to map out how data will flow through the system. A well-defined data flow ensures clarity and helps optimize performance.
Key Components of Data Flow:
- Ingestion: The process of loading raw data into Snowflake. This could be through batch loading (using
COPYcommands) or real-time streaming (using Snowpipe). - Transformation: Snowflake allows you to transform data directly within the platform using SQL. Transformations can range from simple aggregations to complex joins and data cleansing.
- Storage: Snowflake stores data in cloud-native storage formats, ensuring high availability and low latency.
- Access: After transformation, data is ready to be consumed by end-users or systems for reporting, analytics, or machine learning.
Step 2: Design for Scalability
One of Snowflake’s biggest advantages is its scalability. To design scalable data pipelines, you need to focus on how to efficiently manage large datasets and handle fluctuating workloads.
Best Practices for Scalable Pipelines:
- Virtual Warehouses: Snowflake allows you to define compute resources using virtual warehouses. For scalable data pipelines, use the right-sized virtual warehouses for your workloads. You can create multiple warehouses for different types of tasks (e.g., ETL, querying, reporting) and auto-scale based on usage.
- Partitioning and Clustering: Large datasets can be optimized for performance with partitioning and clustering keys. Properly partitioning data reduces query times by improving the efficiency of filter operations. For instance, clustering a sales table by
SalesDatecan speed up time-based queries. - Automatic Scaling: Snowflake’s auto-scaling feature enables warehouses to automatically scale up or down based on workload. This ensures that you only pay for the compute resources you use.
- Data Caching: Leverage Snowflake’s automatic result caching to speed up queries on frequently accessed data, minimizing compute costs and reducing latency.
Step 3: Optimize Data Transformation
Transforming raw data into actionable insights is a critical part of any data pipeline. Snowflake allows you to perform data transformations with SQL, but optimizing these transformations is key to pipeline efficiency.
Optimization Techniques:
Use CTEs for Modular Queries: Common Table Expressions (CTEs) help break complex queries into smaller, reusable components. This improves readability and makes it easier to debug

Minimize Data Shuffling: Avoid excessive data movement or joins that require shuffling between clusters. Use Snowflake’s join optimization techniques such as minimizing cross-cluster joins.
Parallel Processing: Snowflake’s architecture supports parallel processing, which is crucial for efficiently processing large data sets. Designing Data Pipelines to leverage parallel tasks when applicable.
Step 4: Automate Data Pipelines
Once your Designing Data Pipelines is designed, the next step is to automate it to ensure it runs consistently and efficiently.
Automation Tools for Snowflake Pipelines:
- Snowpipe: Snowflake’s continuous data ingestion service, Snowpipe, allows you to automate data loading. Snowpipe listens to cloud storage events and automatically loads data into Snowflake as soon as it’s available.
- External Orchestrators: Snowflake integrates with popular orchestration tools like Apache Airflow, Matillion, and dbt to automate workflows, manage dependencies, and schedule pipeline execution.
- Scheduled Tasks: Use Snowflake’s Task Scheduler to run queries on a predefined schedule. This is particularly useful for batch ETL workflows, such as running data transformation processes every night.
Step 5: Monitor and Maintain Your Pipeline
Once your Designing Data Pipelines is live, it’s important to continuously monitor its performance and ensure it’s running as expected.
Monitoring Techniques:
- Query Profiling: Use Snowflake’s Query Profile feature to monitor the execution of queries in real time. The profile shows detailed insights into query performance, allowing you to identify bottlenecks and optimize queries.
- System Usage: Monitor system usage, including compute resource consumption and storage costs. This will help you adjust resources as needed to keep costs under control.
- Error Handling and Logging: Set up proper error handling mechanisms and logging to track failures or issues in the pipeline. You can automate retries and notifications for failed tasks.
Final Thoughts
Designing data pipelines in Snowflake requires careful planning, optimization, and ongoing maintenance to ensure scalability and performance. By leveraging Snowflake’s powerful features, such as virtual warehouses, clustering, and real-time ingestion with Snowpipe, you can build pipelines that are both cost-effective and efficient.
With the right architecture, transformation techniques, and monitoring strategies, your Snowflake Designing Data Pipelines will not only scale with your data but will also provide accurate and timely insights to support your business objectives.
Ready to start building your scalable Designing Data Pipelines in Snowflake? Contact Locus IT Services for expert consulting and training on designing high-performance data pipelines tailored to your organization’s needs.