

Snowflake has emerged as one of the leading cloud data platforms, offering unique features and capabilities that differentiate it from traditional data warehouses. It is designed to operate natively in the cloud and can scale seamlessly with the increasing demands of modern data-driven organizations. Understanding Snowflake architecture is essential for anyone looking to fully leverage its potential. In this blog post, we will introduce Snowflake architecture, its core components, and how it simplifies data management and analytics.
What is Snowflake?
Snowflake is a cloud-based data warehousing solution designed to handle massive volumes of structured and semi-structured data. Unlike traditional databases, Snowflake is built for the cloud, offering scalability, flexibility, and performance without the complexity of managing hardware. It offers a powerful platform for data analytics, business intelligence, and machine learning applications. (Ref: Monitoring Query Performance with Snowflake’s Query Profile)
Core Components of Snowflake Architecture
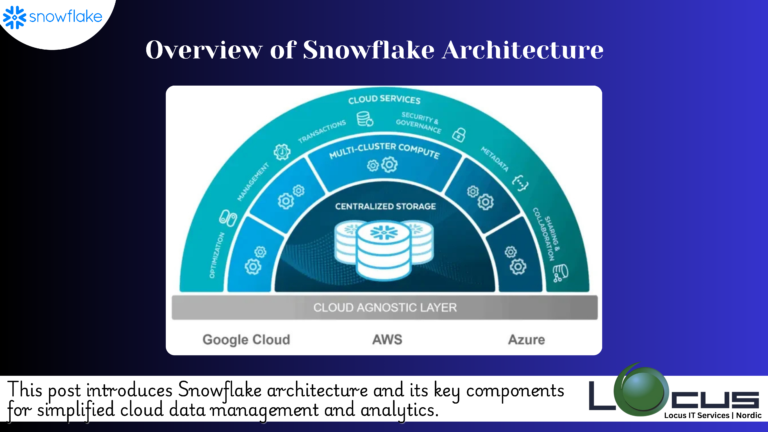
Snowflake architecture is distinct due to its innovative separation of storage, compute, and cloud services, which provides several advantages like scalability, performance optimization, and resource isolation. Let’s take a closer look at the three main layers:
1. Storage Layer
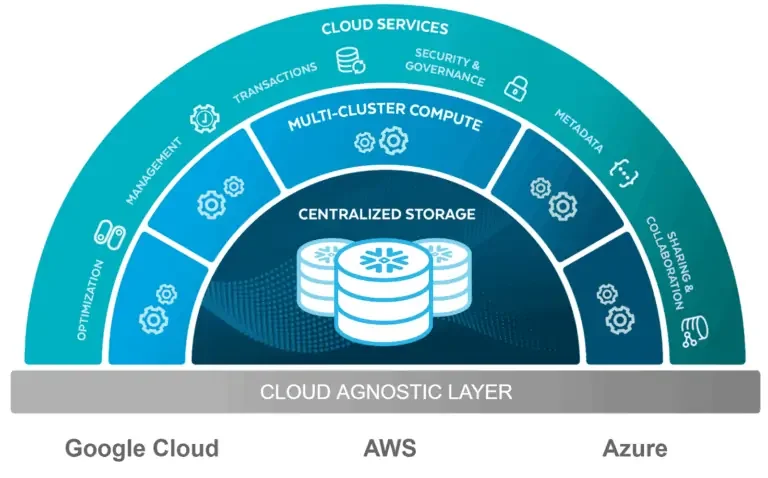
The storage layer is where Snowflake stores all the data, including structured, semi-structured, and unstructured data. Snowflake uses an optimized, columnar storage format that ensures efficient data storage and retrieval. The architecture of Snowflake architecture storage layer enables automatic scaling, which means that as your data grows, Snowflake can automatically scale its storage capacity without manual intervention.
Key Features of Storage:
- Data is stored in cloud storage services like AWS S3, Azure Blob Storage, or Google Cloud Storage.
- Automatic data compression reduces storage costs and improves performance.
- Separation of storage and compute allows you to scale storage independently from compute resources.
2. Compute Layer (Virtual Warehouses)
The compute layer is where data processing happens. Snowflake utilizes virtual warehouses, which are clusters of compute resources, to execute queries, load data, and perform data transformations. The beauty of Snowflake’s compute layer is that it allows you to scale compute resources up or down based on your workload requirements, without affecting the underlying data storage.
Key Features of Compute:
- Virtual Warehouses: Each virtual warehouse runs independently, ensuring that different tasks (such as querying, loading, or transforming data) do not impact each other.
- Elastic Scaling: Snowflake automatically scales virtual warehouses to match the workload, allowing for high concurrency without resource contention.
- Multi-cluster Warehouses: You can set up multiple clusters within a virtual warehouse to handle high concurrency, ensuring consistent query performance even during peak demand.
3. Cloud Services Layer
The cloud services layer manages the infrastructure and coordinates activities across Snowflake. This includes query optimization, transaction management, metadata management, security, and more. The cloud services layer interacts with both the storage and compute layers to facilitate smooth operations. It also includes the metadata repository that stores metadata for all databases, schemas, and tables.
Key Features of Cloud Services:
- Automatic Query Optimization: The cloud services layer analyzes queries in real-time and applies intelligent optimization techniques to ensure queries are executed efficiently.
- Data Sharing and Collaboration: Snowflake architecture allows for secure and easy data sharing between organizations, enabling real-time collaboration.
- Security: This layer handles data encryption, user authentication, access control, and auditing, ensuring that your data remains secure.
Benefits of Snowflake Architecture
Snowflake’s unique architecture offers several key benefits:

- Scalability: The separation of storage and compute allows you to scale resources independently. This means you can grow your storage without impacting the performance of your queries, and you can scale compute power as needed to handle large workloads.
- Concurrency: Snowflake’s multi-cluster architecture ensures that high levels of concurrency do not affect performance. Different virtual warehouses can work simultaneously without competing for resources, making it ideal for organizations with many users or departments running different workloads.
- Performance: With automatic scaling, query optimization, and result caching, Snowflake ensures that your queries run efficiently and with minimal latency.
- Cost Efficiency: The ability to scale compute resources up or down based on actual demand means you only pay for what you use. This pay-as-you-go model ensures you’re not overpaying for unused resources.
- Ease of Use: Snowflake architecture simplifies data management. It abstracts much of the complexity involved in maintaining hardware or setting up clusters, allowing users to focus on their data rather than managing infrastructure.
Final Thoughts
Understanding Snowflake architecture is crucial for organizations looking to adopt the platform for their data storage, analysis, and reporting needs. Its separation of storage, compute, and cloud services provides flexibility, scalability, and performance optimization, making it a powerful tool for managing data in the cloud. As data needs continue to grow, Snowflake architecture will remain a key enabler for businesses to leverage their data effectively and efficiently.
If you’re looking to dive deeper into Snowflake architecture, keep an eye out for additional resources and best practices to ensure you’re fully optimizing the platform for your specific use cases.