

For Every Business, Machine learning (ML) has become a pivotal component of modern data science. As datasets grow larger and algorithms become more sophisticated, efficiently scaling ML Pipelines in R is critical to handling complex data workflows. R, a powerful language for data analysis, provides a rich ecosystem of tools and libraries to help data scientists and engineers scale their ML models. However, as data volume and complexity increase, ensuring that your machine learning pipeline is scalable and efficient becomes paramount.
In this blog post, we will explore the best practices and strategies for scaling ML Pipelines in R, focusing on techniques that optimize performance, streamline processes, and handle large datasets effectively.
What is a Machine Learning Pipeline?

A ML Pipelines in R is a series of steps that automate the flow of data from preprocessing through to model deployment. It typically involves stages such as:
- Data Collection: Gathering raw data from various sources.
- Data Preprocessing: Cleaning and transforming the data into a usable format.
- Feature Engineering: Creating relevant features that improve model performance.
- Model Training: Applying ML Pipelines in R algorithms to the preprocessed data.
- Model Evaluation: Assessing the model’s performance.
- Model Deployment: Putting the trained model into production.
Each of these stages must be automated and optimized to handle increasing data volume, complexity, and user demands. (Ref: Avoiding Loops with Vectorized Operations in R)
Challenges of Scaling Machine Learning Pipelines
Before we dive into solutions, it’s essential to understand the challenges that come with scaling ML Pipelines in R:
- Large Datasets: As datasets grow, memory and processing time constraints become significant bottlenecks.
- Computational Power: Some ML algorithms require extensive computational power, which may not be available on a single machine.
- Data Imbalance: Handling imbalanced data in large-scale pipelines becomes more complex and time-consuming.
- Model Complexity: Complex models, especially deep learning algorithms, require parallel processing and distributed computing.
- Automation: Managing and automating large and complex pipelines can be cumbersome without the right tools.
Best Practices for Scaling ML Pipelines in R
Scaling your ML pipeline effectively in R involves combining different strategies, tools, and technologies to optimize each step. Let’s look at some of the best practices.
1. Efficient Data Preprocessing
One of the primary bottlenecks in any ML Pipelines in R is data preprocessing. When handling large datasets, performing preprocessing steps efficiently is key to scaling your pipeline.
- Data Sampling: If working with very large datasets, consider using data sampling to train your models on a subset of the data that is representative of the whole.
- Parallel Processing: Utilize parallel processing to speed up data preprocessing. The
parallelpackage in R allows you to parallelize tasks such as reading large files, performing transformations, and aggregating data. - In-Memory Databases: When working with large datasets that do not fit into memory, use databases like SQLite or PostgreSQL that can handle large data efficiently. R can interact with these databases using packages such as DBI and dplyr.
2. Leveraging Efficient Data Structures
R provides several specialized data structures for handling large datasets efficiently. Using these data structures will allow your ML Pipelines in R to scale with ease.
- Data Table: The
data.tablepackage provides a highly optimized version of R’s default data frame, allowing faster aggregation, subsetting, and sorting. - Matrices for Numeric Data: When working with large datasets of numerical data, using matrices instead of data frames can improve performance, as matrices are more efficient for numerical computations.
3. Parallel and Distributed Computing
Scaling ML Pipelines in R often involves running computations across multiple cores or distributed systems. This can significantly improve training times and the efficiency of your pipeline.
- Parallel Processing with
foreach: Use theforeachpackage in combination withdoParallelto run iterations of a loop in parallel. This is especially helpful for hyperparameter tuning or running cross-validation on large datasets.
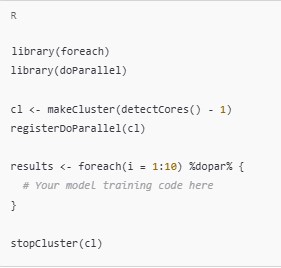
- Hadoop and Spark Integration: ML Pipelines in R can integrate with big data tools like Hadoop and Spark using packages like sparklyr and rhadoop. These tools can distribute computations across clusters, making it easier to handle massive datasets. Spark, in particular, can perform in-memory processing, which speeds up many machine learning tasks.
4. Cloud-Based Solutions
When scaling ML Pipelines in R, especially for large datasets and complex models, cloud-based solutions offer a convenient and powerful option.
- R on Cloud Platforms: You can leverage cloud platforms like AWS, Azure, or Google Cloud to scale your ML pipelines. These platforms allow you to access high-performance compute resources and storage that can handle big data.
- Using Docker and Kubernetes: Docker and Kubernetes are tools that allow you to package your R environment and run it across multiple cloud instances, providing portability and scalability for your ML Pipelines in R. Using containers ensures that your R environment is consistent, making it easier to deploy and scale your models across different systems.
5. Model Optimization
Optimizing ML Pipelines in R is crucial for both accuracy and efficiency. Optimized models not only reduce computation time but also improve overall pipeline scalability.
- Hyperparameter Tuning: Use
caretormlrfor automated hyperparameter tuning. Grid search or random search methods allow you to test different configurations and find the best-performing model with minimal computational cost. - Feature Selection: Reducing the dimensionality of your feature set can improve model performance and speed. Techniques like Principal Component Analysis (PCA) or recursive feature elimination can help you focus on the most important features and discard irrelevant ones.
6. Automating and Monitoring Pipelines
Automation is key to managing large-scale ML pipelines. Tools like airflow and drake can help you automate pipeline steps, from data preprocessing to model deployment, ensuring a smooth and efficient flow.
- drake Package: The drake package helps automate the steps in your ML Pipelines in R, track dependencies, and ensure reproducibility. It works by building workflows that are rerun only when necessary, making it ideal for large pipelines.
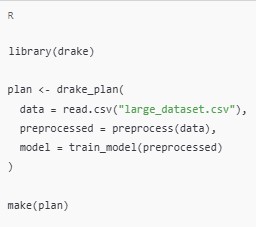
7. Model Deployment and Scalability
Once the model is trained, deploying it efficiently is another crucial step in scaling. Models that are deployed on a single server might struggle with large user loads or complex requests.
- API Integration: Use plumber to turn your R model into a REST API, enabling users to query the model for predictions without needing to interact directly with the R code.
- Scalable Deployment on Cloud: Deploy your trained model on cloud platforms like AWS SageMaker or Azure ML to handle large-scale inference requests, ensuring that your pipeline can handle high traffic and large datasets.
Final Thoughts
Scaling ML Pipelines in R requires the effective use of parallel processing, optimized data structures, cloud computing, and automation tools. By leveraging these strategies, you can ensure that your machine learning workflows are capable of handling large datasets, complex models, and high demands.
Whether you’re working on large-scale data analytics or deploying machine learning models in production, mastering these best practices for scaling ML Pipelines in R will empower you to create faster, more efficient workflows that can tackle real-world challenges. (Ref : Locus IT Services)