

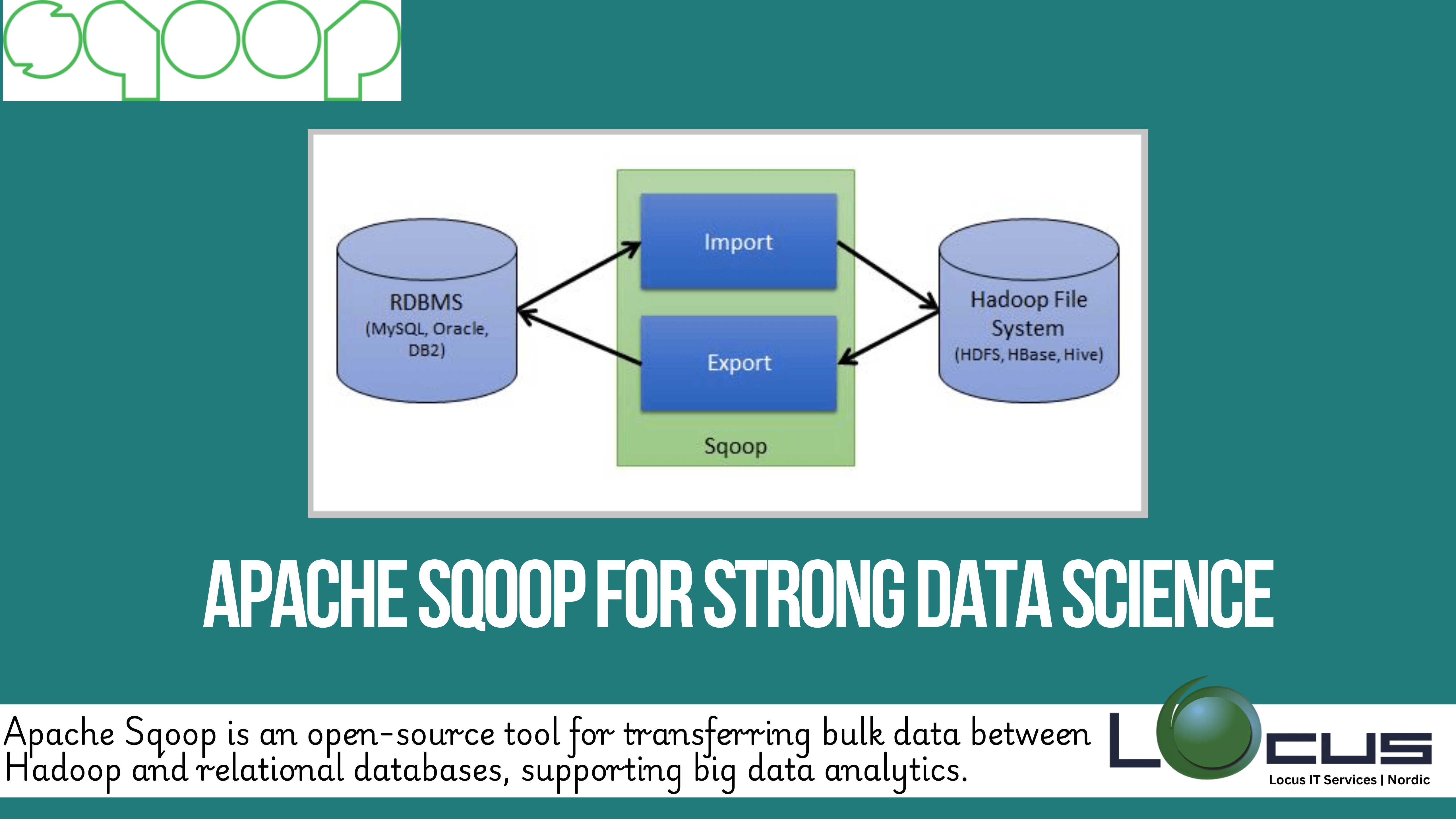
Apache Sqoop is an open-source tool that is used to efficiently transfer bulk data between Apache Hadoop and structured data stores such as relational databases (RDBMS) and data warehouses. Sqoop is particularly valuable in data science workflows that involve the integration of large-scale data stored in relational databases with the Hadoop ecosystem for advanced analytics and big data processing.
Table of Contents
Key Features of Apache Sqoop for Data Science:

- Efficient Data Transfer:
- Bulk Data Import/Export: Sqoop is designed to handle the bulk transfer of data, allowing data scientists to import large datasets from relational databases into Hadoop Distributed File System (HDFS), and export processed data back to relational databases. This capability is essential for moving data between systems for analytics, reporting, and machine learning. (Ref: Hadoop Distributed File System HDFS for Data Science)
- Parallel Data Transfer: Sqoop optimizes data transfer by splitting datasets into smaller chunks and using multiple mappers to transfer data in parallel. This parallelism ensures that large datasets are imported or exported efficiently, minimizing the time required for data movement.
- Integration with Hadoop Ecosystem:
- HDFS Integration: Sqoop imports data directly into HDFS, making it accessible for further processing with Hadoop tools like Apache Hive, Apache Pig, and Apache Spark. This integration allows data scientists to leverage Hadoop’s distributed computing capabilities for large-scale data processing and analysis.
- Hive and HBase Integration: Sqoop can import data directly into Apache Hive tables or Apache HBase, enabling structured data to be easily queried and analyzed using SQL-like languages (HiveQL) or integrated with NoSQL data in HBase. This is particularly useful for data warehousing and real-time analytics.
- Data Transformation:
- Data Transformation During Import: Sqoop allows data transformations during the import process. Data scientists can apply SQL queries to filter, join, or aggregate data as it is being imported into Hadoop, reducing the need for subsequent processing steps in Hadoop.
- Field Mapping and Type Conversion: Sqoop supports field mapping and type conversion, allowing data scientists to map database fields to Hadoop-compatible formats and convert data types during the import/export process.
- Incremental Data Import:
- Incremental Load: Sqoop supports incremental data imports, which is critical for keeping Hadoop data stores in sync with relational databases. Data scientists can schedule regular imports of new or updated data, ensuring that their data lake or data warehouse remains up-to-date without re-importing entire datasets.
- Integration with Data Warehouses:
- Data Export to RDBMS: In addition to importing data into Hadoop, Sqoop can export processed data from Hadoop back to relational databases. This is useful for pushing insights, aggregated results, or transformed data back into enterprise databases or data warehouses for reporting and decision-making.
- Support for Popular Databases: Sqoop supports a wide range of relational databases, including MySQL, PostgreSQL, Oracle, SQL Server, and DB2, making it versatile for data integration across different database systems.
- Customizable and Extensible:
- Connectors: Sqoop uses connectors to interface with different databases. It comes with built-in connectors for popular databases and also supports custom connectors, allowing data scientists to extend Sqoop’s functionality to support additional databases or customize data transfer behavior.
- Integration with Oozie: Sqoop can be integrated with Apache Oozie, a workflow scheduler for Hadoop, allowing data scientists to automate and schedule Sqoop jobs as part of a larger data processing pipeline.
- Data Security:
- Secure Data Transfer: Sqoop supports secure data transfer using JDBC and ODBC connectors with SSL encryption, ensuring that sensitive data is securely moved between relational databases and Hadoop.
- Authentication and Authorization: Sqoop integrates with Hadoop’s security mechanisms, including Kerberos authentication, to ensure that only authorized users can perform data transfers.
Use Cases of Apache Sqoop in Data Science:
- Data Ingestion for Big Data Analytics:
- Populating Data Lakes: Data scientists can use Sqoop to import large volumes of data from enterprise databases into Hadoop-based data lakes. This data can then be processed, analyzed, and stored in Hadoop for advanced analytics, machine learning, and data mining tasks.
- Aggregating Data for Analytics: Sqoop enables the aggregation of data from multiple relational databases into a single Hadoop environment, facilitating cross-database analytics and the creation of unified datasets for comprehensive analysis.
- Data Warehousing:
- Loading Data into Hive: Sqoop is often used to load data into Apache Hive tables, enabling SQL-based querying of structured data within Hadoop. Data scientists can analyze large datasets using HiveQL, perform joins, aggregations, and other SQL operations, and then export the results back to relational databases or reporting tools.
- Exporting Results to Databases: After processing data in Hadoop, Sqoop can export the results back to relational databases or data warehouses. This allows processed data to be integrated into existing business intelligence (BI) systems for reporting and decision-making.
- Machine Learning and Data Preparation:
- Preparing Data for Machine Learning: Sqoop can import data from databases into Hadoop, where data scientists can clean, transform, and engineer features for machine learning models. The processed data can then be used to train models using Apache Spark MLlib or other machine learning frameworks in Hadoop.
- Exporting Model Predictions: After generating predictions or insights using machine learning models in Hadoop, Sqoop can export these results back to relational databases, enabling integration with business applications and decision-making processes.
- Data Synchronization and ETL:
- Incremental Data Loading: Sqoop’s support for incremental imports allows data scientists to keep Hadoop datasets in sync with source databases by regularly importing only new or updated records. This is useful for ETL processes where data needs to be refreshed frequently.
- Automated ETL Workflows: Sqoop can be integrated into automated ETL workflows using tools like Apache Oozie, enabling scheduled data transfers and transformations as part of a broader data processing pipeline.
- Cross-Platform Data Analysis:
- Integrating RDBMS with Hadoop: Data scientists often work with data stored in both relational databases and Hadoop. Sqoop facilitates the integration of these platforms, enabling cross-platform data analysis where data can be seamlessly transferred between systems for comprehensive analytics.
Advantages of Apache Sqoop for Data Science:
- Efficient Data Transfer: Sqoop’s ability to handle large-scale, parallel data transfers makes it ideal for moving vast amounts of data between relational databases and Hadoop, enabling efficient data ingestion and export.
- Integration with Hadoop: Sqoop’s deep integration with the Hadoop ecosystem allows data scientists to leverage Hadoop’s processing power for big data analytics, while still using relational databases for storage and retrieval.
- Simplified Data Migration: Sqoop simplifies the process of migrating data between different systems, reducing the complexity and time required for data integration tasks.
- Incremental Loading: The ability to perform incremental data loads ensures that Hadoop datasets remain up-to-date with minimal overhead, making it easier to maintain data consistency across systems.
Challenges:
- Batch-Oriented: Sqoop is designed for batch processing and may not be suitable for real-time data integration or streaming applications. Data scientists needing real-time data movement might need to complement Sqoop with other tools like Apache Kafka.
- Complexity in Configuration: Configuring Sqoop for optimal performance can be complex, particularly when dealing with large datasets or integrating with multiple databases. Fine-tuning may be required to achieve the best results.
- Learning Curve: While Sqoop abstracts much of the complexity of data transfer, there is still a learning curve, particularly for data scientists unfamiliar with Hadoop or database administration.
Comparison to Other Tools:
- Sqoop vs. Apache NiFi: Apache NiFi is a data flow management tool that supports real-time data ingestion, transformation, and routing across various systems. While Sqoop is optimized for batch data transfer between RDBMS and Hadoop, NiFi is more versatile for real-time data flows and complex data routing scenarios.
- Sqoop vs. Talend: Talend is an ETL (Extract, Transform, Load) tool that provides a graphical interface for designing data integration workflows. While Talend offers broader data integration capabilities with support for multiple data sources, Sqoop is more specialized for efficient bulk data transfer between relational databases and Hadoop.
- Sqoop vs. Apache Flume: Apache Flume is designed for ingesting log data into Hadoop in real-time. While Flume is suitable for streaming log data, Sqoop is better suited for transferring large datasets from relational databases to Hadoop in batch mode.
Apache Sqoop is a powerful tool for data scientists working in Hadoop environments, providing an efficient and scalable way to transfer large datasets between relational databases and Hadoop. Its integration with the Hadoop ecosystem, support for incremental data loading, and ability to handle complex data transformations make it an essential tool for data ingestion, ETL, and cross-platform data analysis. While it is primarily focused on batch processing, Sqoop’s ability to facilitate the seamless movement of data between different systems is invaluable for data science projects that involve large-scale data integration and processing.