

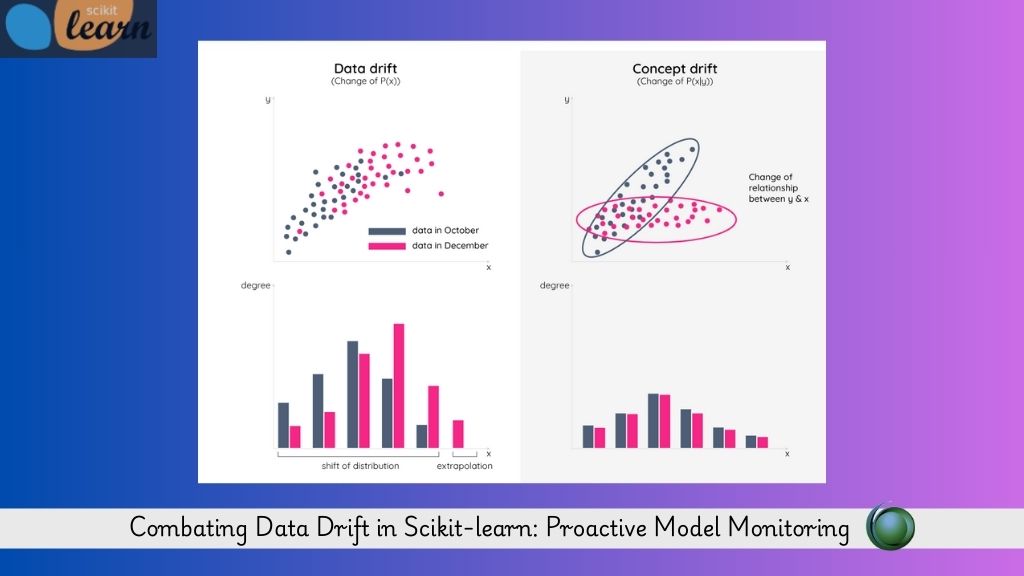
In the rapidly evolving world of machine learning, model accuracy is often treated as the benchmark of success. However, even the most most precise models can deteriorate once deployed if underlying data patterns shift. This phenomenon, known as data drift can silently compromise Scikit-learn models without any built-in warning system. For IT professionals managing critical analytics pipelines, this is a crucially important to look after. In this blog, we’ll explore why mastering data drift in Scikit-learn is essential, where the framework falls short, and how to adopts robust monitoring strategies.
Importance of Data Drift in Scikit-learn Models

Machine learning models assume that the data they see during training is similar to what they’ll encounter in production. But in real-world scenarios, data is fluid. Customer behavior, market trends, operational processes everything evolves. In Scikit-learn, models are typically trained and deployed without built-in mechanisms to grow continuously evaluate input distributions. Which means:
- Model might continue predicting, unaware that it’s now working with outdated assumptions.
- Performance metrics degrade slowly, often only discovered after serious business impact.
This leads to delayed detection of poor decisions, loss of revenue or incorrect insights.
Common Causes of Data Drift in Scikit-learn
Data Drift is not always a statistical inference, but it can also be the stem from a serious operational inconsistencies, such as:
- Changes in Data Collection: New sensors, APIs, or frontend updates altering feature values.
- Evolving User Behavior: Shifts in user patterns that weren’t captured in training data.
- Concept Drift: When the relationship between input and output changes over time.
- Data Leakage: Training data unintentionally includes future or unseen information.
In Scikit-learn environments where batch inference is common, these issues can easily go unnoticed especially when there is no real time performance monitoring.
What Scikit-learn Lacks in Drift Detection
Scikit-learn is a robust library known for its versatility, but model monitoring is not one of it’s salient feature. Sometimes, it also does not provide:
- Alert for data distribution changes
- Monitoring dashboards for live input features
- Concept drift detection across time windows
Developers are supposed to build their own monitoring solutions, which is time-consuming and often deprioritized.

Meet Locus IT’s Monitoring Services: Real-Time Drift Alerts & Mitigation
This is where Locus IT Services steps in. We bridge the gap between Scikit-learn’s training prowess and real-world production demands. With our custom monitoring dashboards, you can — Track live input feature distributions and detect significant shifts, receive real-time alerts when a feature diverges from training norms, identify the input drift and prediction drift using statistical tests and thresholds and also integrate with your CI pipeline for automated model retraining. Book now
Case Example: Business Impact of Undetected Drift
Consider a recommendation engine built using Scikit-learn that was trained on 6 months of user behavior data. After being deployed for 3 month:
- A frontend UI change subtly altered how user preferences were logged.
- These new values skewed predictions toward less relevant products.
- The drop in conversion wasn’t traced to the model until weeks later.
Had drift detection been used, the issue would have been flagged within hours, saving both revenue and customer trust.
Proactive Strategies to Combat Data Drift in Scikit-learn
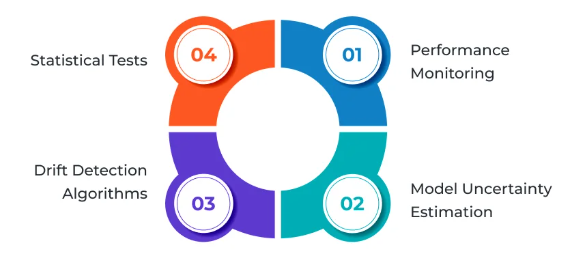
There are several strategies that can be implemented alongside Scikit-learn to tackle drift:
Statistical Tests for Distribution Shifts: Incorporate tools like Kolmogorov-Smirnov (KS) tests or Jensen-Shannon divergence to compare training and live data distributions.
Baseline Performance Monitoring: Set up rolling windows to compare current model accuracy against historical performance. Sudden drops can be early indicators of drift
Shadow Models: Run new models in the background alongside the deployed version. Differences in predictions can uncover drift or leakage early.
Feature Importance Monitoring: Monitor how much influence each feature has over time. A sudden change in top features often signals data instability.
Pipeline Automation: Use platforms like MLflow or Apache Airflow to automate retraining when performance thresholds are breached.
How Locus IT Enhances These Strategies
While the above mentioned strategies are effective, their implementation can be time-intensive for lean teams. Locus IT offers end-to-end drift solutions, including pre-built pipelines for drift and leakage detection, customized Scikit-learn integration for your business logic, support for cloud-native deployment (AWS, Azure, GCP), periodic audits to ensure model health across your ML lifecycle.
We also provide consulting services for teams aiming to scale up their ML infrastructure while ensuring resilience hidden model decay.
Conclusion: Stay Ahead of Drift with Locus IT’s Expert Services
In today’s data-driven economy, letting your models silently decay due to drift or leakage is a risk most business can’t afford. Scikit-learn is an excellent modeling framework, but it needs support when it comes to production monitoring and reliability.
By partnering with Locus IT, you can not only combat data drift but also stay one step ahead of it. Let your machine learning systems be as agile as your business needs.