

In today’s AI-driven world, the ability in Scaling TensorFlow workloads directly influences how fast organizations can innovate and deploy powerful machine learning models. However, as datasets grow larger and models become increasingly complex, traditional single-node training often becomes a bottleneck. This is where distributed computing steps in. By strategically scaling across multiple devices or nodes, businesses can amplify TensorFlow training, accelerate results, and achieve superior model performance — all while optimizing infrastructure costs.
In this context, we’ll dive into how distributed TensorFlow can supercharge the model training and how to approach scaling effectively for real-world success.
Why Scaling TensorFlow Workloads Matters
When we amplify TensorFlow training, we unlock multiple critical advantages:
- Faster Model Convergence: Distributing workloads reduces the time needed for model training.
- Handle Larger Datasets: Go beyond the memory limitations of a single machine.
- Improve Experimentation Speed: More experiments mean better models.
- Efficient Resource Utilization: Balance loads across CPUs, GPUs, or TPUs for maximum performance.
- Distributed computing — spreading the workload across multiple machines or devices allows TensorFlow users to dramatically boost speed, efficiency, and model performance.

The Role of Distributed Computing in Scaling TensorFlow Workloads
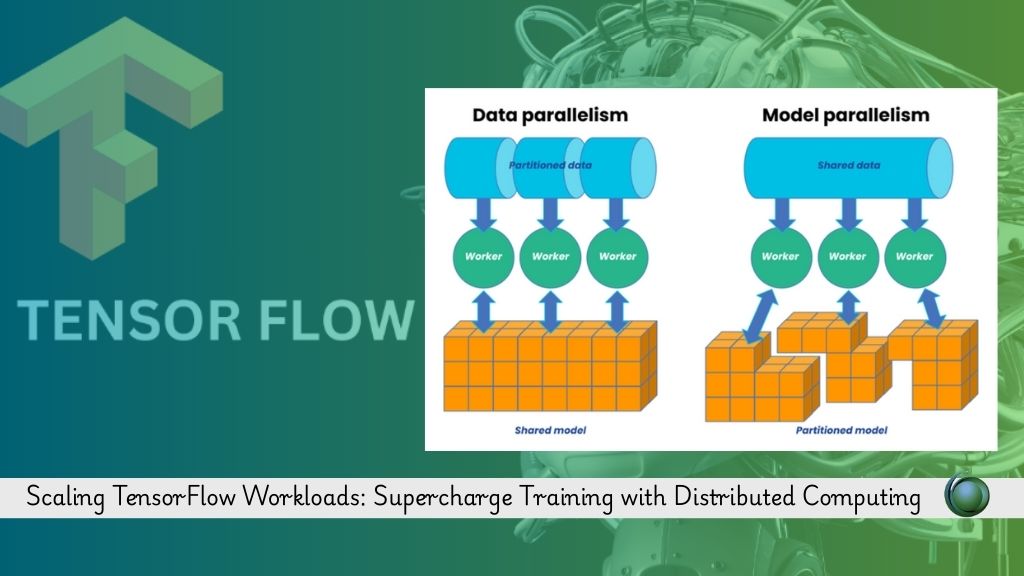
Distributed computing is not just a performance booster, its a strategic move for scaling AI workloads efficiently. Techniques such as data parallelism, model parallelism, and parameter server architectures allow engineers to divide tasks and optimize communication between machines.
When organizations amplify TensorFlow training using distributed frameworks like Horovod, TensorFlow Mirrored Strategy, or Multi-Worker Mirrored Strategy, they can:
- Train models across multiple GPUs or TPU pods seamlessly.
- Reduce training times from weeks to days or even hours.
- Minimize overfitting by processing larger batch sizes without losing accuracy.
Meet Locus IT Services: Industry Specific Analytics Solutions
If your AI models take too long to train because of huge amounts of data, think about using our team of TensorFlow experts who work remotely. When your main team is busy building and improving your AI products, we can step in. Our remote engineers know how to make TensorFlow training much faster using multiple computers working together. This means your big models will train quicker, and your team can focus on making your AI even better – without getting slowed down by training times. Let Locus IT handle the heavy lifting of making your TensorFlow training fast and efficient!
How Offshore Experts Help Scaling TensorFlow Training
Scaling TensorFlow workloads requires deep expertise in distributed architectures, system tuning, and framework optimization. Partnering with offshore TensorFlow specialists ensures you tap into proven experience while keeping costs predictable.
Our offshore engineers help you:
- Architect scalable TensorFlow pipelines tailored to your infrastructure.
- Implement distributed training strategies with minimal downtime.
- Optimize resource usage to amplify TensorFlow training without ballooning compute expenses.
- Troubleshoot bottlenecks during large-scale training experiments.
By collaborating with offshore experts, your teams can focus more on innovation while we handle the heavy lifting of distributed computing.
TensorFlow Strategies for Distributed Training
TensorFlow provides several built-in strategies to help manage distributed computing efficiently:
1. MirroredStrategy
Ideal for single-machine multi-GPU setups.
Replicates the model across GPUs on the same machine and synchronizes updates efficiently.

2. MultiWorkerMirroredStrategy
Best for multiple machines training in parallel.
Highly scalable for larger setups in clusters or cloud platforms.

3. TPUStrategy
If you’re using Tensor Processing Units (TPUs) in Google Cloud or on-premises, this strategy makes it easy to distribute workloads across TPU cores.

Common Challenges in Scaling TensorFlow and How We Solve Them
Even with powerful tools, amplifying TensorFlow training can encounter roadblocks:
- Communication Overheads: Improper synchronization across nodes can slow down training.
- Imbalanced Data Splits: Leads to inefficient parallelism.
- Debugging Distributed Failures: Complex errors occur when scaling across many devices.
Our offshore teams specialize in addressing these challenges by:
- Tuning communication protocols like NCCL, gRPC, or MPI.
- Using smart dataset sharing techniques.
- Implementing fault-tolerant distributed systems with automatic retries.
We ensure that scaling up TensorFlow workloads isn’t just possible — it’s efficient and reliable.
Real Benefits: Why Companies Are Choosing to Amplify TensorFlow Training Now
Across industries — from healthcare and fintech to autonomous driving — organizations are realizing that slower model training directly translates to missed market opportunities.
Amplifying TensorFlow training brings:
- First-mover Advantage: Deploy better models faster than competitors.
- Cost Optimization: Avoid overpaying for compute by using distributed strategies efficiently.
- Team Empowerment: Allow data scientists to focus on modeling rather than infrastructure headaches.
Ready to Amplify TensorFlow Training with Experts?

At Locus It services, we specialize in helping businesses to scale TensorFlow training with powerful distributed computing strategies. Whether you’re aiming to cut model training times in half or efficiently manage massive datasets, our offshore engineers are ready to elevate your AI capabilities.