

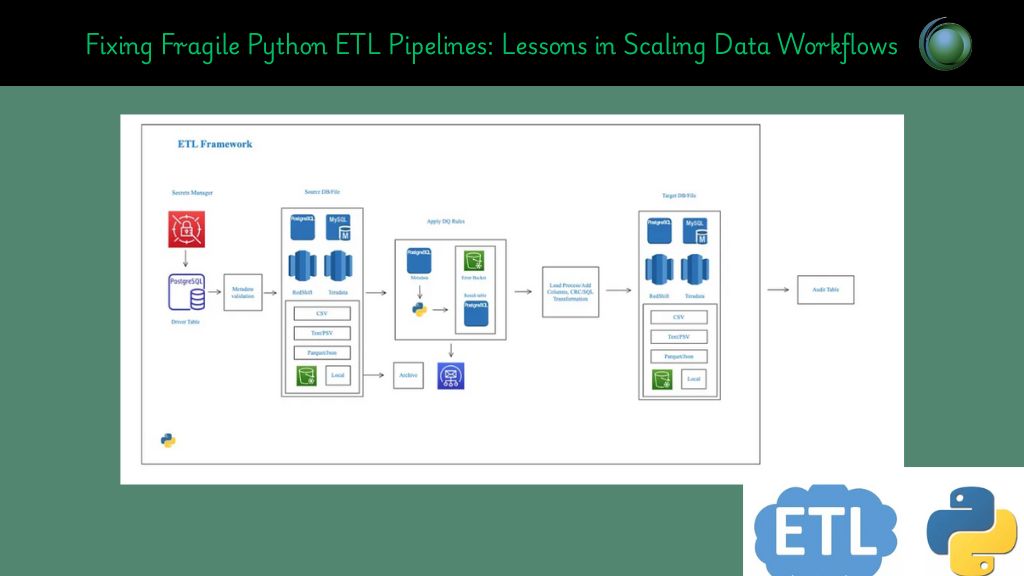
Python has become a cornerstone for building ETL (Extract, Transform, Load) workflows to maintain a clean syntax, active ecosystem, and libraries like pandas, sqlalchemy, and pyodbc. While Python ETL pipelines work brilliantly for small, one-off tasks or prototype analytics, they often begin to falter when applied to production-scale data environments.
At scale, the nature of data evolves it becomes messier, more voluminous, more distributed, and more time-sensitive. Suddenly, the script that worked in your Jupyter notebook is plagued by memory errors, API timeouts, missed schedules, and silent data quality issues. This blog explores why Python ETL pipelines break at scale, and how modern data engineering tools-especially when implemented by experts like Locus IT-can provide the architecture and stability needed to support enterprise grade pipelines.
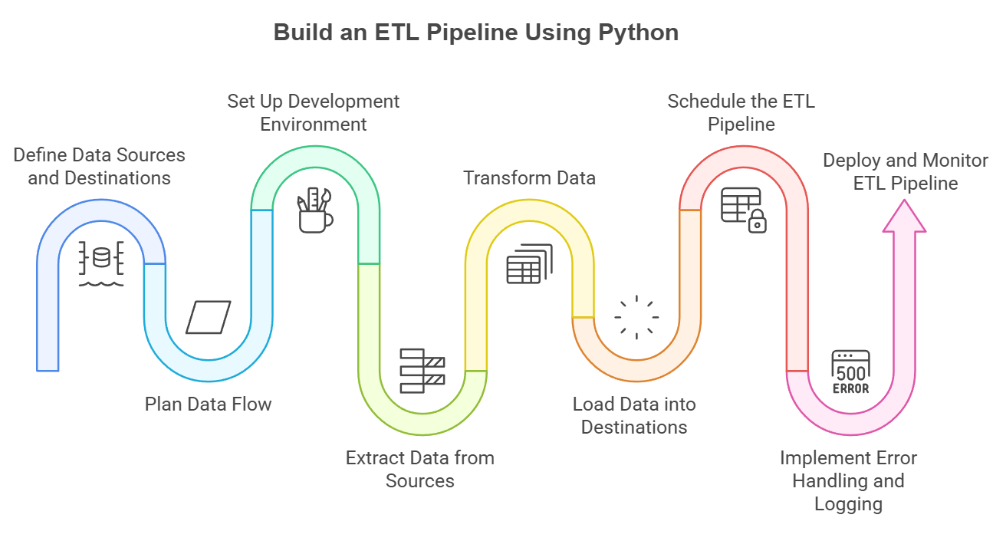
Memory Limits and the Fall of In-Memory Processing
One of the most common bottlenecks in Python ETL pipelines stems from the assumption that entire datasets can comfortably reside in memory. Libraries like pandas are memory-bound, which means as datasets grow into gigabytes or terabytes, processing them in-memory becomes unsustainable.
This limitation often manifests in the form of sluggish performance, out-of-memory errors, and unpredictable behavior under load. Data engineers may initially try to work around this using hacks like increasing RAM or breaking files into chunks, but these are temporary fixes at best. In practice, scaling Python ETL pipelines demands a shift from local processing to distributed computing frameworks such as Apache Spark. Platforms like Databricks, which offer native PySpark support, allow data processing to scale horizontally across compute nodes—making operations faster and fault-tolerant.
Locus IT helps organizations transition from monolithic pandas-based scripts to distributed data workflows on Databricks, enabling pipelines to handle enterprise-scale data without crumbling under pressure.
The Orchestration Challenge: From Cron to Chaos
In small projects, Python ETL jobs are often executed via cron jobs or manual triggers. While this might suffice for occasional tasks, it lacks the structure, visibility, and reliability required for continuous, business-critical data operations. Without orchestration, it becomes impossible to manage task dependencies, monitor failures, or scale execution across teams and time zones.
Workflow orchestrators like Apache Airflow solve this problem by treating your ETL process as a Directed Acyclic Graph (DAG). They manage scheduling, retries, logging, and inter-task communication with precision. Airflow allows you to define your ETL logic as modular, reusable components—essential for long-term maintainability.
Locus IT Pitch: From Prototype to Production
Locus IT offers production-grade Airflow implementations, integrating monitoring tools and dynamic DAG generation to help teams avoid the chaos that ensues when ad-hoc job scheduling no longer scales. Book Now!

Schema Drift and the Cost of Fragile Transformation

At scale, data sources are rarely stable. APIs evolve, databases are updated, and CSV formats subtly change. Yet most Python ETL pipelines are built under the assumption of static schemas, often hardcoding data cleaning and transformation logic. The result is pipelines that quietly produce incorrect data or break outright when structure shifts go undetected.
This issue, known as schema drift, can only be addressed through validation frameworks and test-driven data processing. By implementing schema enforcement using tools like pydantic, Cerberus, or Great Expectations, engineers can catch issues early in the pipeline before they propagate into downstream systems.
Locus IT specializes in integrating these validation layers within scalable ETL pipelines, enabling enterprises to safeguard data quality and maintain integrity even as upstream sources evolve.
APIs at Scale: A Hidden Operational Risk
ETL pipelines often pull data from external APIs, ranging from SaaS platforms to public data services. While Python’s requests library makes API integration straightforward, it hides deeper complexities such as rate limits, intermittent timeouts, and authentication lapses. These problems rarely emerge during development but can wreak havoc when APIs are called at high frequencies in production.
As teams scale their ETL operations, API interactions must be treated as unreliable by default. Implementing retries, backoff strategies, and asynchronous execution becomes essential. In some cases, buffering data through message queues like Kafka or RabbitMQ can help absorb transient failures and decouple ingestion from processing.
Through its consulting services, Locus IT helps clients architect resilient API ingestion pipelines that incorporate these best practices, ensuring data pipelines remain robust even when external systems are unpredictable.
Observability: The Silent Killer of Broken Pipelines
Perhaps the most underappreciated element in ETL pipelines is observability. Without proper logging, alerting, and monitoring, even the most sophisticated Python ETL pipelines can silently fail or produce incorrect data with no one noticing until business operations are impacted.
Observability is about more than just logs—it’s about structured metrics, data lineage, and SLA enforcement. Monitoring tools like Prometheus, Grafana, and OpenLineage can be integrated into ETL workflows to offer end-to-end transparency. Knowing when a pipeline failed is useful; knowing why it failed and what was affected downstream is critical.
Locus IT Pitch: Accelerating Your Python ETL Pipelines
Locus IT ensures observability is baked into every pipeline it builds, giving IT teams the visibility they need to diagnose, debug, and resolve issues quickly and confidently.
Cloud-Native Scalability: From Python Scripts to Data Platforms
Another major turning point in scaling Python ETL pipelines is infrastructure. Scripts that once ran fine on local machines or EC2 instances may now need distributed compute, autoscaling, and fault tolerance. Many organizations delay these infrastructure upgrades until performance becomes unbearable.
Building cloud-native ETL pipelines means embracing tools like Databricks Jobs, serverless compute options like AWS Lambda, and containerized workflows orchestrated via Kubernetes. These paradigms allow pipelines to scale elastically with workload demands while reducing operational overhead.
Locus IT assists organizations in this transformation—migrating legacy workflows to high-availability cloud platforms, optimizing resource allocation, and integrating DevOps practices for deployment automation.
Conclusion: Scaling Python ETL Pipelines with Confidence
The journey from small-scale Python scripts to enterprise-scale ETL pipelines is riddled with challenges: memory constraints, fragile orchestration, API bottlenecks, schema drift, and lack of observability. Left unaddressed, these issues can delay data availability, erode trust, and increase operational costs.
However, with the right architectural choices—and the right partner—these challenges can be overcome. Tools like Airflow and Databricks provide the technological backbone, but what truly makes a difference is experienced guidance.
Locus IT offers end-to-end expertise in building, scaling, and maintaining robust Python ETL pipelines. Whether you’re migrating from legacy systems, optimizing for performance, or starting fresh with a cloud-native stack, Locus IT ensures your pipelines are resilient, observable, and built to scale.
References: https://en.wikipedia.org/wiki/Python_(programming_language)