

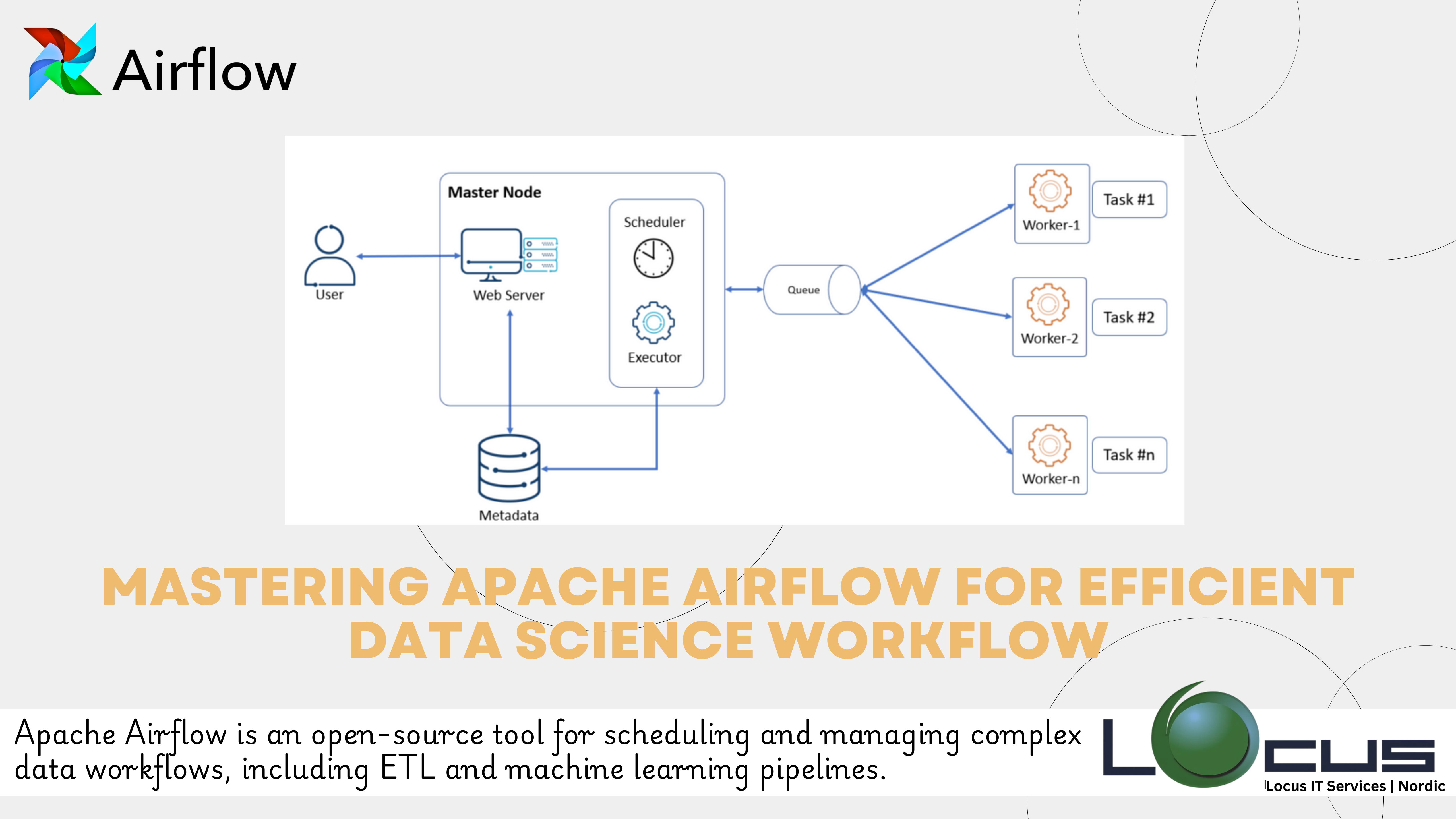
Apache Airflow is an open-source platform used to programmatically author, schedule, and monitor workflows. It is particularly well-suited for data science and engineering tasks where complex data pipelines need to be orchestrated, automated, and managed. Airflow allows users to define workflows as Directed Acyclic Graphs (DAGs), where each node represents a task, and the edges represent dependencies between those tasks. This makes Apache Airflow a powerful tool for managing ETL processes, machine learning pipelines, and other data-driven workflows.
Table of Contents
Key Features of Apache Airflow for Data Science:

- Workflow Orchestration with DAGs:
- Directed Acyclic Graphs (DAGs): In Airflow, workflows are defined as DAGs, where each task is a node, and dependencies are edges. This structure allows data scientists to define complex workflows with clear dependencies and execution order, ensuring that tasks are executed in the correct sequence.
- Task Dependencies: Airflow allows you to set dependencies between tasks, ensuring that certain tasks only start after others have successfully completed. This is crucial for data science workflows where data needs to be processed, cleaned, and transformed before analysis or model training.
- Extensible Python-Based Framework:
- Pythonic Approach: Airflow is written in Python, and workflows (DAGs) are defined using Python scripts. This makes it highly extensible and easy for data scientists who are already familiar with Python to integrate custom scripts, libraries, and APIs directly into their workflows.
- Custom Operators and Plugins: Airflow supports custom operators, sensors, and plugins, allowing data scientists to extend its functionality to meet specific needs. This is useful for integrating Airflow with specialized tools, databases, or external APIs.
- Scheduling and Automation:
- Flexible Scheduling: Apache Airflow provides powerful scheduling options, allowing workflows to be triggered at specific times, intervals, or based on external events. This ensures that data pipelines run automatically according to a defined schedule, reducing manual intervention.
- Backfilling: Apache Airflow supports backfilling, allowing you to run past DAG runs to fill in gaps or reprocess data. This is useful for scenarios where you need to rerun workflows due to changes in upstream data or logic.
- Monitoring and Alerting:
- Real-Time Monitoring: Apache Airflow web-based user interface provides real-time monitoring of workflows, allowing data scientists to track the status of each task, visualize the DAG, and view logs. This makes it easy to identify and troubleshoot issues in the workflow.
- Alerts and Notifications: Apache Airflow supports alerts and notifications via email, Slack, or other messaging platforms when tasks fail, succeed, or encounter issues. This ensures that data scientists are immediately aware of any problems in the workflow and can take action as needed.
- Scalability and Parallelism:
- Task Parallelism: Apache Airflow allows tasks to be executed in parallel, maximizing resource utilization and reducing the overall time required to complete workflows. This is particularly beneficial for data science tasks that can be parallelized, such as data processing or model training.
- Scalable Architecture: Apache architecture is designed to scale horizontally, allowing it to handle large and complex workflows. It can be deployed on a single machine or across a distributed cluster, making it suitable for both small teams and large enterprises.
- Integration with Data and Cloud Ecosystems:
- Database and Cloud Integrations: Airflow comes with built-in operators for interacting with databases, cloud storage, and cloud services (e.g., AWS, GCP, Azure). This makes it easy to move data between systems, trigger cloud functions, or orchestrate multi-cloud workflows.
- Support for Big Data Tools: Airflow integrates with big data tools like Apache Hive, Apache Spark, and Presto, allowing data scientists to orchestrate ETL processes that involve large datasets and complex transformations.
- Data Lineage and Auditability:
- Data Lineage Tracking: Airflow’s DAGs inherently provide a form of data lineage, as they clearly show the flow of data and the dependencies between tasks. This transparency helps data scientists understand the movement and transformation of data throughout the pipeline.
- Audit Trails: Airflow logs all actions and events, providing a comprehensive audit trail. This is useful for compliance and troubleshooting, as it allows you to track who ran what workflows and when.
- Support for Dynamic and Complex Workflows:
- Dynamic DAG Generation: Airflow allows for the dynamic generation of DAGs, enabling the creation of workflows that adapt to different input parameters or data conditions. This is useful for data science scenarios where workflows need to be flexible and data-driven.
- Branching and Conditional Execution: Airflow supports conditional task execution, where the workflow can branch into different paths based on the outcome of previous tasks. This allows for more complex decision-making within data pipelines.
- Versioning and Collaboration:
- Version Control: Since Airflow DAGs are defined in Python scripts, they can be version-controlled using Git or other version control systems. This enables collaboration among data science teams and ensures that workflows are consistent and reproducible.
- Environment Isolation: Airflow can be deployed in isolated environments, such as virtual machines or containers, ensuring that workflows have a consistent runtime environment and reducing the risk of conflicts between dependencies.
- Extensibility and Customization:
- Custom Hooks and Operators: Airflow supports the creation of custom hooks and operators that can interact with external systems, APIs, or data sources. This extensibility allows data scientists to tailor Airflow to their specific needs.
- Plugins: Airflow’s plugin architecture allows for the addition of custom features, such as user interface extensions, custom executors, or integration with external systems. This makes it possible to enhance Airflow’s capabilities beyond the core functionality.
Use Cases of Apache Airflow in Data Science:
- ETL Pipelines:
- Data Ingestion and Transformation: Airflow is commonly used to orchestrate ETL pipelines, where data is ingested from various sources, transformed according to business rules, and loaded into data warehouses or data lakes. Airflow ensures that each step in the pipeline is executed in the correct order and that any dependencies are respected.
- Data Quality Checks: Airflow can be used to automate data quality checks as part of the ETL process. For example, tasks can be added to validate data, check for missing values, or compare datasets before proceeding to the next step.
- Machine Learning Pipelines:
- Model Training and Evaluation: Airflow can orchestrate machine learning workflows, from data preprocessing and feature engineering to model training and evaluation. Data scientists can automate the entire machine learning pipeline, ensuring that models are trained and evaluated consistently.
- Hyperparameter Tuning: Airflow can be used to manage hyperparameter tuning experiments, where multiple models with different hyperparameters are trained in parallel. This allows for efficient exploration of the hyperparameter space and selection of the best model.
- Data Integration and Synchronization:
- Cross-System Data Integration: Airflow can be used to synchronize data between different systems, such as databases, cloud storage, and third-party APIs. This is useful for keeping data up-to-date and consistent across platforms, enabling integrated data analysis.
- API Data Fetching: Airflow can automate the process of fetching data from external APIs, transforming it, and storing it in a database or data lake for further analysis.
- Business Intelligence and Reporting:
- Automated Reporting: Airflow can schedule and automate the generation of reports and dashboards, ensuring that stakeholders have access to up-to-date insights. Data pipelines can be set up to refresh data sources, run analytics queries, and generate reports at regular intervals.
- Data Aggregation and Analysis: Airflow can orchestrate workflows that aggregate data from various sources, perform complex analyses, and store the results in a format suitable for visualization or reporting.
- Data Science Experimentation and Collaboration:
- Experiment Management: Airflow can be used to manage and track data science experiments, ensuring that different versions of data processing scripts, models, and results are documented and reproducible. This supports collaborative work among data science teams.
- Notebook Automation: Airflow can automate the execution of Jupyter notebooks, allowing data scientists to run and schedule notebook-based workflows as part of a larger data pipeline.
- Monitoring and Anomaly Detection:
- Real-Time Monitoring: Airflow can orchestrate real-time data monitoring workflows, where data streams are continuously analyzed for anomalies, trends, or patterns. This is useful for detecting issues early, such as data quality problems or unusual behavior in production systems.
- Alerting and Incident Response: Airflow can be configured to trigger alerts and incident response workflows based on the detection of specific conditions, such as threshold breaches or errors in data processing.
Advantages of Apache Airflow for Data Science:
- Flexibility and Extensibility: Airflow’s Python-based DAGs and support for custom operators make it highly flexible and adaptable to a wide range of data science tasks and workflows.
- Scalability: Airflow is designed to scale, making it suitable for both small-scale projects and large enterprise workflows. It can be deployed in various environments, from a single machine to a distributed cluster.
- Comprehensive Monitoring and Logging: Airflow’s web interface and logging capabilities provide excellent visibility into workflow execution, making it easier to monitor progress, troubleshoot issues, and optimize performance.
- Strong Community and Ecosystem: As an open-source project, Airflow has a large and active community, with regular updates, plugins, and integrations being developed. This ensures that Airflow remains a cutting-edge tool for workflow orchestration.
Challenges:
- Learning Curve: While Airflow is powerful, it can have a steep learning curve, particularly for users who are not familiar with Python or the concept of DAGs. Understanding how to design and optimize workflows effectively can take time.
- Complexity in Large Deployments: Managing Airflow in large, distributed environments can be complex, requiring careful configuration and management of resources, dependencies, and infrastructure.
- Performance Overhead: For very large or highly parallel workflows, Airflow may introduce some performance overhead, particularly if not properly tuned. Ensuring that tasks are efficiently scheduled and resources are effectively utilized is crucial.
Comparison to Other Tools:
- Airflow vs. Luigi: Luigi is another workflow orchestration tool that is similar to Airflow but is generally considered more lightweight and easier to set up. However, Airflow offers a more robust set of features, a more modern web interface, and better scalability, making it a better choice for more complex or larger-scale workflows.
- Airflow vs. Prefect: Prefect is a newer workflow orchestration tool that offers a more modern approach with features like task-level retries and more intuitive handling of state. Prefect also offers a cloud-based version for easier management. While Airflow has a larger community and more integrations, Prefect’s simplicity and modern design make it appealing for certain use cases.
- Airflow vs. Kubeflow Pipelines: Kubeflow Pipelines is a platform specifically designed for orchestrating machine learning workflows on Kubernetes. While Airflow is more general-purpose and can be used for a wide range of workflows, Kubeflow Pipelines offers tighter integration with Kubernetes and machine learning tools, making it ideal for ML-specific workflows.
Apache Airflow is a powerful and versatile tool for orchestrating complex data science (Ref:Hortonworks) workflows. Its flexibility, scalability, and extensive integration capabilities make it a popular choice for managing ETL processes, machine learning pipelines, and other data-driven tasks. While it comes with a learning curve and requires careful management in large deployments, Airflow’s ability to automate, monitor, and optimize workflows is invaluable for data scientists looking to build reliable, scalable, and reproducible data pipelines. As an open-source platform with a strong community, Airflow continues to evolve, offering new features and integrations that keep it at the forefront of workflow orchestration tools.