

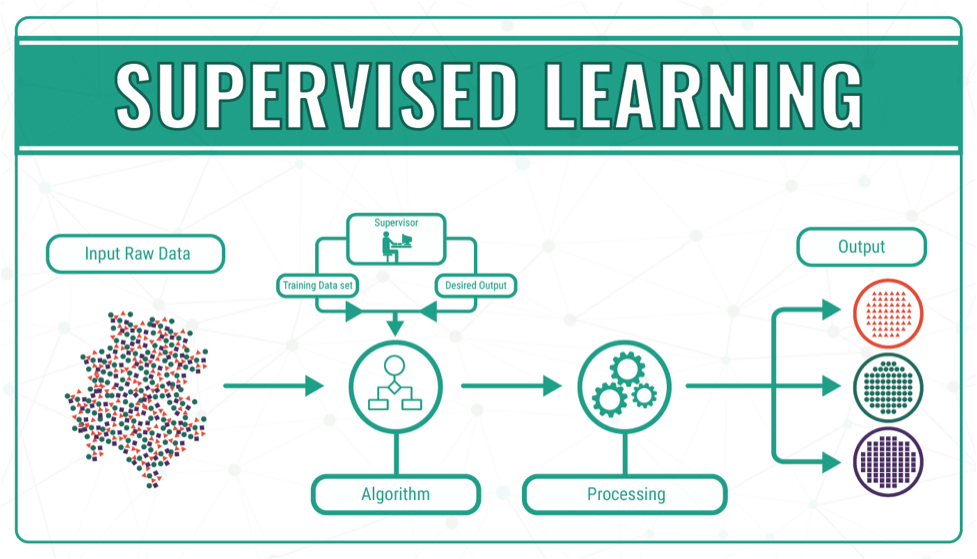
Supervised learning is one of the most fundamental and widely used approaches in machine learning. It’s a technique where a model is trained on labeled data, meaning that the input data comes with corresponding output labels. In supervised learning, the goal is to learn a mapping from inputs to outputs so that the model can make predictions on new, unseen data. Python, with its rich ecosystem of libraries, provides a versatile environment for implementing supervised learning algorithms. In this blog post, we’ll explore the concept of supervised learning and how Python can be used to build powerful models for a wide range of applications.
What is Supervised Learning?
In supervised learning, the “supervision” refers to the use of labeled data to train a model. The data consists of input-output pairs, where the input features (or variables) are mapped to a known output (or label). The objective is for the model to learn the relationship between these inputs and outputs so that it can accurately predict the output for new, unseen inputs.
Supervised learning can be broadly divided into two types:
- Classification: This is used when the output variable is categorical. For example, classifying emails as “spam” or “not spam”, or predicting whether a patient has a particular disease based on medical data.
- Regression: This is used when the output variable is continuous. An example might be predicting house prices based on features such as square footage, location, and number of bedrooms.
How Does Supervised Learning Work in Python?
Python’s simplicity and powerful libraries make it an ideal language for implementing supervised learning algorithms. Here’s how you would typically work with supervised learning in Python:
- Data Collection and Preparation
The first step in any supervised learning task is to collect and prepare your data. In Python, data is often handled using libraries such as Pandas, which provides powerful tools for manipulating datasets. Once the data is loaded, you can preprocess it by cleaning, normalizing, and splitting it into training and testing sets. - Feature Selection and Engineering
Selecting the most relevant features is crucial to building an efficient model. Python libraries such as Scikit-learn provide tools for feature selection, while Pandas and NumPy allow you to engineer new features from existing data. Good feature engineering can greatly improve the model’s predictive power. - Model Selection
After preparing the data, the next step is to choose a suitable supervised learning algorithm. Python offers a broad range of models for both classification and regression tasks. Some popular algorithms include: (Ref: Transform Machine Learning Workflows with Python ML Pipelines)- Logistic Regression: Used for binary or multiclass classification tasks.
- Decision Trees: Intuitive models that split the data based on feature values.
- Random Forest: An ensemble of decision trees that improves accuracy and handles overfitting.
- Support Vector Machines (SVM): A powerful classifier that works well with both linear and non-linear data.
- Linear Regression: Commonly used for regression tasks, predicting continuous output.
- k-Nearest Neighbors (k-NN): A non-parametric algorithm that classifies based on the closest data points.
- Training the Model
Once the model is chosen, it is trained using the labeled training data. The goal during training is to adjust the model’s parameters to minimize the error between predicted and actual outputs. Python’s Scikit-learn provides easy-to-use interfaces for training models, and most algorithms come with built-in support for cross-validation, helping to avoid overfitting. - Model Evaluation
After training the model, it’s important to evaluate its performance on unseen data (usually the testing set). Python provides a variety of metrics to assess model performance:- Accuracy: The proportion of correct predictions for classification tasks.
- Precision and Recall: Important metrics for imbalanced datasets, especially in classification.
- Mean Squared Error (MSE): A common metric for evaluating regression models.
- Confusion Matrix: A table used for classification tasks to visualize performance.
- R-squared: A statistical measure for regression tasks, indicating how well the model explains the variance in the data.
- Model Tuning and Optimization
Once you have a trained model, the next step is to tune its hyperparameters. Hyperparameter tuning can significantly improve model performance. Python libraries such as GridSearchCV and RandomizedSearchCV in Scikit-learn help find the optimal hyperparameters by exhaustively searching over a specified parameter grid or randomly selecting hyperparameter combinations. - Mean Squared Error
After training and evaluating the model, the final step is to deploy it into production for real-time predictions. Python offers tools such as Flask or Django to wrap models in web applications, or TensorFlow Serving for deploying deep learning models in production.
Advantages of Supervised Learning with Python

- Wide Range of Algorithms
Python’s rich ecosystem provides access to a wide variety of supervised learning algorithms, from simple models like logistic regression to more complex ones like support vector machines and random forests. - Ease of Use
Python is renowned for its simplicity and readability, making it easy to quickly experiment with different algorithms and tweak models for better performance. - Robust Libraries
Python offers powerful libraries such as Scikit-learn, TensorFlow, Keras, and PyTorch, all of which facilitate the development of supervised learning models with minimal boilerplate code. These libraries also offer extensive documentation, making it easier for both beginners and advanced users to get started with machine learning. - Scalability
Python supports parallel and distributed computing through libraries like Dask and Joblib, allowing you to scale your supervised learning models to handle large datasets without compromising performance. - Community Support
Python’s machine learning community is large and active. You can find numerous tutorials, forums, and research papers that help guide you through supervised learning concepts, making it easier to learn and troubleshoot.
Applications of Supervised Learning in Python
Supervised learning in Python has countless real-world applications across various industries. Some examples include:
- Finance: Predicting stock prices, detecting fraudulent transactions, and assessing credit risk.
- Healthcare: Diagnosing diseases, predicting patient outcomes, and analyzing medical images.
- Marketing: Customer segmentation, sentiment analysis, and recommendation systems.
- E-commerce: Predicting product demand, customer behavior analysis, and personalized recommendations.
- Autonomous Vehicles: Classifying road signs, detecting obstacles, and identifying pedestrian movement patterns.
Final Thoughts
Supervised learning is a cornerstone of machine learning, enabling machines to make accurate predictions based on historical data. Python’s versatility and rich ecosystem make it an excellent choice for implementing supervised learning models. With the right tools and techniques, you can leverage supervised learning to tackle a wide range of problems, from simple classification tasks to complex predictive modeling. Whether you’re a beginner or an experienced data scientist, Python’s simplicity and power will allow you to build models that are both efficient and scalable, opening up endless possibilities for your machine learning projects.