

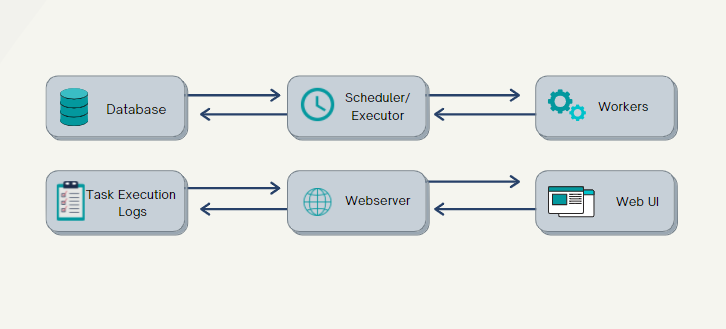
Apache Airflow has revolutionized workflow orchestration by offering a powerful framework for scheduling, monitoring, and managing complex workflows. At the heart of Airflow’s functionality are operators and tasks, the fundamental components that define how workflows are executed.
In this blog post, we’ll explore what Airflow operators and tasks are, their key types, and how they play a critical role in building and orchestrating workflows effectively.
What Are Operators in Apache Airflow?
An Airflow operators Airflow is a predefined template that specifies a single unit of work. Operators define what a task should do but not how it runs. Each operator is tied to a specific action, like running a Python function, executing a SQL query, or moving files. (Ref: Airflow Data Engineering Best Practices)
Operators are idempotent, meaning they produce the same result no matter how many times they are executed. This ensures consistency and reliability in workflows.
Types of Operators
Airflow provides a variety of Airflow operators to handle different types of tasks. Here are some commonly used categories:
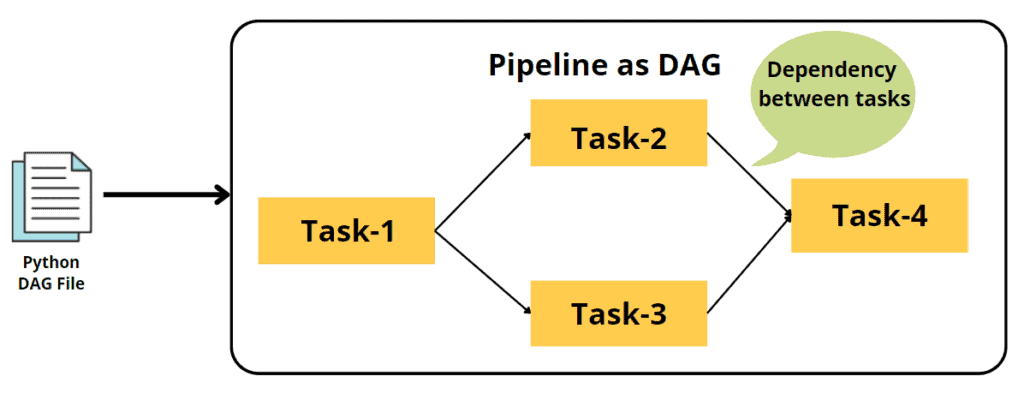
- Action Operators
These perform specific actions like running Python scripts, shell commands, or SQL queries. Examples include:- PythonOperator: Executes Python functions.
- BashOperator: Runs Bash shell commands.
- PostgresOperator: Executes SQL queries on a PostgreSQL database.
- Transfer Operators
These handle data transfers between systems. Examples include:- S3ToGCSOperator: Moves files from Amazon S3 to Google Cloud Storage.
- GoogleCloudStorageToBigQueryOperator: Loads data from Google Cloud Storage into BigQuery.
- Sensor Operators
Sensors are a special type of operator that waits for a certain condition to be met before proceeding. Examples include:- FileSensor: Waits for a file to appear in a specified location.
- ExternalTaskSensor: Waits for a task in a different DAG to complete.
- Custom Operators
For use cases not covered by built-in operators, you can create custom operators. These are particularly useful for workflows with unique requirements, such as integrating with proprietary systems.
What Are Tasks in Apache Airflow?
A task is an instance of an operator in a Directed Acyclic Graph (DAG). Tasks define the actual execution of the work specified by the Airflow operators. Each task in a DAG represents a single step in the workflow.
Tasks are connected to each other through dependencies, forming the flow of execution. For example, in a data pipeline, one task might extract data from a database, another might transform it, and a final task might load it into a data warehouse.
Task Parameters
Tasks have several configurable parameters that define their behavior:
- Retry Policies: Define how many times a task should retry on failure and the delay between retries.
- Execution Timeouts: Specify the maximum time a task is allowed to run before it is considered failed.
- Dependencies: Set relationships between tasks to determine execution order.
Key Differences Between Operators and Tasks
| Feature | Operator | Task |
|---|---|---|
| Definition | Describes a type of work (e.g., run a script, transfer data). | A specific instance of an operator in a DAG. |
| Functionality | Provides a blueprint for what needs to be done. | Executes the defined action in a DAG. |
| Examples | PythonOperator, BashOperator, MySqlOperator | Task1 (using PythonOperator), Task2 (using BashOperator). |
How Airflow operators and Tasks Work Together
Operators and tasks are interlinked:
- You define a DAG (Directed Acyclic Graph) to represent your workflow.
- Within the DAG, you create tasks by instantiating operators.
- Each task executes the logic defined by the operator.
For example, if you want to execute a Python script followed by a SQL query, you would:
- Use the PythonOperator to define a task that runs the script.
- Use the PostgresOperator to define another task that executes the SQL query.
- Connect these tasks using dependencies to ensure they run in the desired order.
Best Practices for Using Airflow operators and Tasks
- Choose the Right Operator
Always use the operator that aligns with the task’s purpose. For example, use a database operator (e.g., MySqlOperator) for SQL queries instead of embedding them in a Python function. - Set Clear Dependencies
Define dependencies between tasks logically to ensure a smooth flow of execution. Use methods likeset_upstream()andset_downstream()to establish relationships. - Limit Task Complexity
Each task should perform a single, clear function. Avoid combining multiple operations into a single task, as it makes debugging and monitoring more difficult. - Implement Retries and Timeouts
Set retry policies and execution timeouts for tasks to handle transient errors and prevent long-running or stuck tasks. - Leverage Sensors Judiciously
Use sensors for tasks that depend on external conditions but be cautious of their resource usage, as they can hold up worker slots while waiting. - Modularize Custom Logic
For tasks requiring custom logic, write Python functions or scripts and pass them to operators like the PythonOperator. This keeps your DAG definitions clean and readable.
Monitoring Airflow operators and Tasks
Airflow operators provides tools to monitor the execution of tasks and workflows:
- Graph View: Visualize the flow of tasks and their statuses (e.g., running, failed, or completed).
- Tree View: View task execution history and progress in a color-coded format.
- Logs: Access detailed logs for each task to diagnose issues and debug failures.
Final Thoughts
Airflow operators and tasks are the building blocks of Apache Airflow workflows, transforming it into a powerful orchestration engine. By understanding their roles and relationships, data engineers can design efficient, scalable workflows that handle complex data pipelines seamlessly.
When used effectively, Airflow operators and tasks simplify orchestration, reduce redundancy, and enhance workflow maintainability, making Airflow an indispensable tool for modern data engineering.