

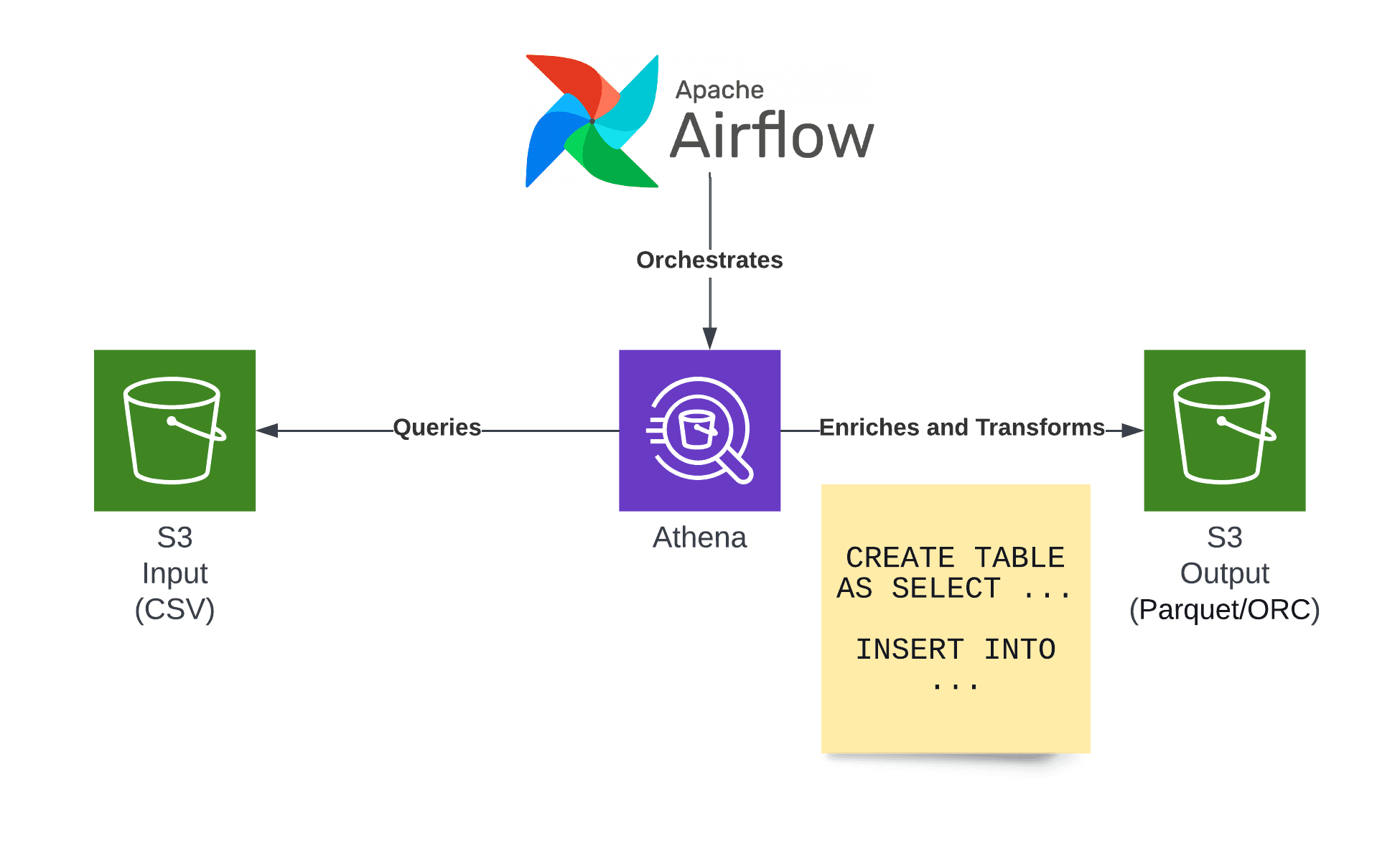
Apache Airflow is a widely used tool for orchestrating complex workflows, and it’s particularly powerful when it comes to automating ETL (Extract, Transform, Load) pipelines. With its ease of use and scalability, Airflow has become a go-to solution for managing and automating data workflows in modern data engineering.
In this blog post, we will explore how you can leverage Apache Airflow to streamline your ETL processes, without delving too deep into code, and making it easy to automate and monitor your data pipelines.
What is ETL in Data Pipelines?
ETL pipelines refers to the process of extracting data from various sources, transforming it into a suitable format, and loading it into a data store like a data warehouse or a data lake. These tasks are typically automated to keep data workflows running efficiently. (Ref: Dynamic Workflows in Apache Airflow)
- Extract: Retrieve data from various data sources (APIs, databases, files, etc.).
- Transform: Cleanse and manipulate the data to fit business needs (aggregation, filtering, etc.).
- Load: Store the transformed data in a destination system like a database or data warehouse.
How Airflow Facilitates ETL Pipelines
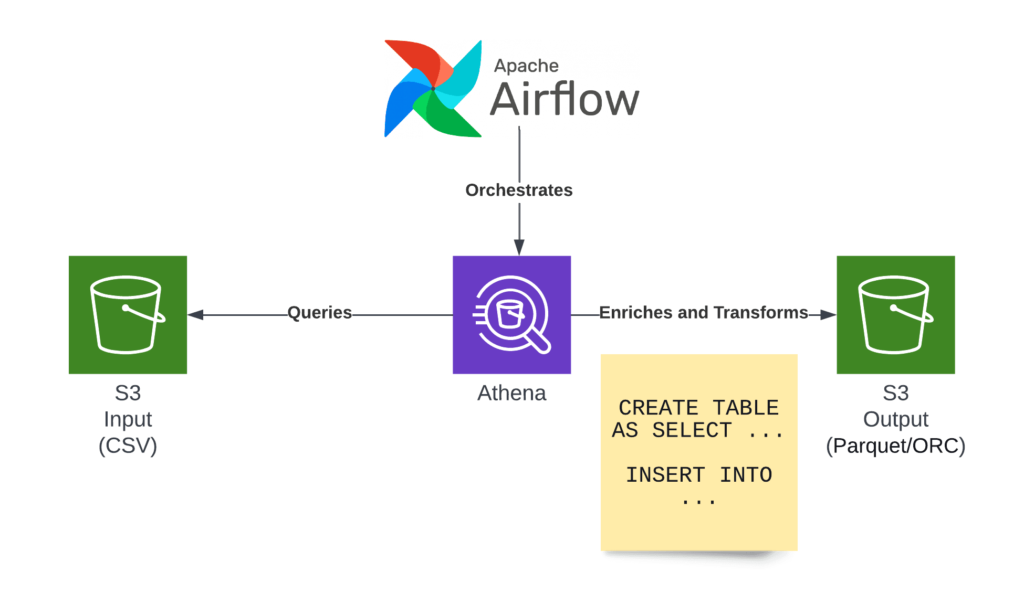
Apache Airflow simplifies the orchestration of ETL tasks by offering a rich set of features, including task scheduling, dependencies management, and integration with a wide range of data sources and systems. Let’s break down how Airflow works for ETL pipelines:
1. Define the Pipeline Using Directed Acyclic Graphs (DAGs)
In Apache Airflow, workflows are defined using Directed Acyclic Graphs (DAGs). A DAG defines the structure of your ETL pipeline and specifies the order in which tasks should run.
Each DAG represents the full ETL process, from data extraction to loading the results into a final storage system.
2. Use Built-in Operators for ETL Tasks
Airflow provides a variety of operators that allow you to perform key ETL pipelines actions with minimal code:
- Extract: Airflow can pull data from multiple sources using operators like
HttpSensorfor API calls,MySqlOperatorfor pulling data from databases, andFileSensorfor watching files in directories. - Transform: Once the data is extracted, you can use operators like
PythonOperatororBashOperatorto transform the data. You can run scripts or commands to clean, filter, or aggregate data. - Load: Airflow offers integration with various destinations. You can use operators like
PostgresOperatororBigQueryOperatorto load data into databases, cloud storage, or other data stores.
3. Automate Task Scheduling
With Airflow, you can automate the scheduling of your ETL pipeline. Whether you need to run the pipeline daily, weekly, or based on an event trigger, you can easily set the execution schedule within the DAG definition.
- Scheduler: Airflow’s scheduler will automatically trigger your DAG at the specified intervals, ensuring that your ETL process runs on time.
4. Manage Task Dependencies
Airflow allows you to set dependencies between tasks, ensuring that they run in the correct sequence. For example, the data extraction task must run before the transformation task, and the transformation must complete before the data is loaded.
- Task Dependencies: Simply set the task order using methods like
task1 >> task2to define task dependencies. Airflow will handle the task scheduling, ensuring that tasks execute in the correct order.
5. Monitor and Handle Failures
Once your ETL pipeline is running, you can monitor its progress in real-time using Airflow’s web interface. The UI provides visibility into task statuses, logs, and even detailed error messages, helping you quickly identify and troubleshoot any issues.
- Task Retries: Airflow supports automatic retries for failed tasks, ensuring that transient issues don’t cause pipeline failures. You can define the number of retries and the delay between them.
Why Use Airflow for ETL Pipelines?
Scalability
Airflow is designed to scale horizontally, meaning you can add more workers to handle larger workloads as your data grows.
Flexibility
Airflow provides extensive support for a variety of data sources and destinations, making it easy to connect with virtually any system. Whether you’re pulling data from a database, an API, or flat files, Airflow has you covered.
Ease of Use
With its user-friendly web interface, Airflow lets you monitor and manage your ETL pipelines without needing deep technical expertise. You can track the progress of each task, view logs, and set up alerts for task failures.
Error Handling and Retries
Airflow’s built-in retry mechanism and alerting system ensure that issues in your ETL pipelines are automatically addressed or escalated, reducing the need for manual intervention.
Basic Example of an Airflow ETL Pipeline (Minimal Code)
Let’s consider a simple ETL pipeline that pulls data from an API, processes it, and loads it into a database.
- Extract: Use the
HttpOperatorto fetch data from an API. - Transform: Use a
PythonOperatorto clean and process the data. - Load: Use the
PostgresOperatorto load the transformed data into a PostgreSQL database.
In a few lines of code, this pipeline can be defined as a DAG in Apache Airflow. Here’s a simplified version:
pythonCopy codefrom airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.http_operator import SimpleHttpOperator
from airflow.providers.postgres.operators.postgres import PostgresOperator
from datetime import datetime
# Define the DAG
dag = DAG('simple_etl_pipeline', start_date=datetime(2024, 1, 1), schedule_interval='@daily')
# Extract: Fetch data from API
extract_data = SimpleHttpOperator(
task_id='extract_data',
method='GET',
endpoint='api/data',
http_conn_id='api_connection',
dag=dag
)
# Transform: Process data using a Python function
def transform_data(*args, **kwargs):
# Custom transformation logic
pass
transform_data_task = PythonOperator(
task_id='transform_data',
python_callable=transform_data,
provide_context=True,
dag=dag
)
# Load: Insert data into PostgreSQL
load_data = PostgresOperator(
task_id='load_data',
sql="INSERT INTO table (column1, column2) VALUES (%s, %s)",
parameters=('value1', 'value2'),
postgres_conn_id='postgres_connection',
autocommit=True,
dag=dag
)
# Set dependencies
extract_data >> transform_data_task >> load_data
Final Thoughts
Apache Airflow simplifies the process of building, scheduling, and managing ETL pipelines. With its powerful set of built-in operators and task management features, you can automate and scale your ETL workflows without writing much code. The flexibility, scalability, and ease of use make Airflow an ideal choice for orchestrating your data pipelines.
By leveraging Airflow’s features like scheduling, task dependencies, error handling, and monitoring, you can ensure that your ETL processes run smoothly, enabling you to focus on deriving value from your data rather than managing the workflow itself.
Start building your own ETL pipelines with Apache Airflow today and unlock the full potential of automation in your data workflows!