

For Every Business data-driven world, organizations are collecting vast amounts of data from various sources. However, the real value of this data comes from analyzing it to derive actionable insights. This is where data warehousing comes into play. A data warehouse is a central repository that allows businesses to store and manage large amounts of structured and historical data, enabling comprehensive business intelligence (BI) and data analysis.
To build a successful data warehousing system, understanding the architecture of data warehouses is critical. The architecture defines how data is collected, processed, stored, and accessed for analytics. In this blog post, we’ll take a closer look at the data warehousing architecture, its components, and how it supports business intelligence.
Table of Contents
What is Data Warehousing Architecture?
Data warehousing architecture refers to the design framework and structure that governs the movement, storage, and accessibility of data within a data warehouse. The architecture is built to ensure that data can be efficiently loaded, transformed, stored, and queried. It typically includes multiple layers and processes that work together to facilitate the extraction, transformation, and analysis of data.
The architecture of a data warehouse is typically divided into several key components or layers. These components ensure that the data is processed effectively and can be used for complex analytical queries and business reporting.
Key Components of Data Warehousing Architecture
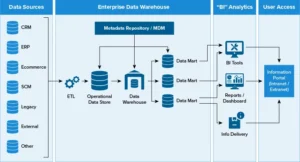
- Data Sources Layer (Source Systems)
The first layer in the data warehousing architecture is the data sources layer, which refers to the various systems and applications where data is collected. These systems could be:
- Operational databases (e.g., CRM, ERP)
- External data sources (e.g., third-party APIs, external feeds)
- Data lakes or big data platforms
- Flat files (e.g., CSV, Excel files)
- Legacy systems
The data in these source systems is typically transactional and real-time, making it necessary to integrate, clean, and transform it before it can be loaded into the data warehouse.
- Data Extraction Layer
The next layer is the data extraction layer, where data is extracted from the source systems for further processing. This stage involves gathering data from different sources, which could be structured, semi-structured, or unstructured. The extraction process typically involves:
- Batch processing: Extracting data at scheduled intervals, such as daily or weekly.
- Real-time processing: Extracting data as it is generated to keep the warehouse up to date.
Tools like ETL (Extract, Transform, Load) platforms or ELT (Extract, Load, Transform) processes play a significant role in this layer.
- Data Transformation Layer
After extraction, the data enters the transformation layer, where it undergoes various processes to cleanse, standardize, and structure it for analysis. This stage ensures that the data is accurate, consistent, and aligned with the warehouse schema.
Key processes in the transformation layer include:
- Data cleansing: Correcting inaccuracies, handling missing data, and eliminating duplicates.
- Data normalization: Converting data into a consistent format or structure.
- Data aggregation: Summarizing data, such as calculating totals or averages, for easier analysis.
- Data validation: Ensuring data meets certain business rules or constraints.
Transformation tools are typically a part of ETL/ELT software, or cloud-based solutions like AWS Glue or Google Cloud Dataflow.
- Data Storage Layer
The data storage layer is where the transformed data is stored in the data warehouse. This is the core repository for all data used for analysis and reporting. The storage layer is typically optimized for analytical workloads, with data structured in a way that enables fast query execution and reporting.
Key elements of the storage layer include:
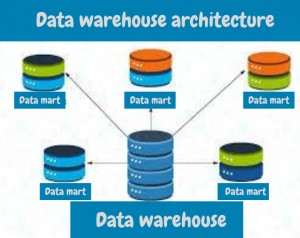
- Data warehouse: The actual database or system where data is stored, often in a columnar format for faster querying.
- Data mart: A subset of the data warehouse focused on a specific business area or department (e.g., sales, finance).
- Indexing: Creating indices for faster search and retrieval of specific data sets.
Modern data warehouses, such as Amazon Redshift, Google BigQuery, and Snowflake, provide high-performance storage solutions that are scalable and cost-effective. (Ref: Snowflake)
- Data Presentation Layer (BI Tools)
The presentation layer is where end users interact with the data for reporting, analysis, and decision-making. It connects the data warehouse with business intelligence (BI) tools, dashboards, and data visualization tools, which present the data in an easy-to-understand format.
Common BI tools used in this layer include:
- Tableau
- Power BI
- Qlik
- Looker
These tools allow users to query the data, create interactive reports, and visualize complex trends and patterns, making the data actionable and helping organizations make data-driven decisions.
- Metadata Layer
The metadata layer contains information about the data in the warehouse. This layer provides descriptions, data definitions, and detailed information about how the data is structured and processed.
The metadata layer is important because it:
- Helps users and administrators understand the data structure, relationships, and sources.
- Assists in data governance by providing insight into data lineage and transformations.
- Facilitates the management and maintenance of the data warehouse.
In many cases, metadata is stored in a separate repository within the data warehouse.
- Data Governance and Security Layer
Given the sensitivity of the data stored in a data warehouse, it is crucial to include a data governance and security layer. This layer ensures that data is handled in compliance with internal policies and regulatory requirements.
Key functions in this layer include:
- Data security: Protecting sensitive data through encryption, authentication, and access control mechanisms.
- Data lineage: Tracking the origin and transformation of data to ensure transparency and accountability.
- Data quality: Continuously monitoring and improving the accuracy, consistency, and reliability of the data.
- Compliance: Ensuring that the data warehouse adheres to regulations like GDPR, HIPAA, or SOX.
Types of Data Warehouse Architectures
There are several types of data warehouse architectures, depending on the complexity and needs of the organization:
- Single-Tier Architecture
This is the simplest form of data warehousing, where all components of the architecture are combined into a single layer. It is typically used for smaller data sets and less complex environments. - Two-Tier Architecture
In a two-tier architecture, the data warehouse and the presentation layer are separated. This model is commonly used in medium-sized organizations with relatively straightforward data management needs. - Three-Tier Architecture
The most common architecture used in modern data warehouses, the three-tier architecture separates the data storage layer, the transformation layer, and the presentation layer into distinct levels. This separation enables scalability, flexibility, and efficiency in managing large volumes of data. - Cloud-Based Architecture
With the rise of cloud computing, many organizations are opting for cloud-based data warehousing solutions. These architectures are flexible, scalable, and cost-effective, providing easy access to data and reducing the need for on-premises hardware. Popular cloud-based platforms include AWS Redshift, Google BigQuery, and Microsoft Azure Synapse.
Final Thoughts
Understanding the data warehousing architecture is crucial for building a successful data warehouse that can handle large amounts of data and provide actionable insights. The architecture is composed of multiple layers that ensure data is efficiently extracted, transformed, stored, and accessed for analysis. Whether your organization uses a traditional on-premises system or a cloud-based solution, having a well-structured architecture is essential for achieving optimal business intelligence and data analysis outcomes.
As data continues to grow in both volume and complexity, designing a scalable, flexible, and secure data warehousing architecture will be key to unlocking the full potential of your organization’s data.