

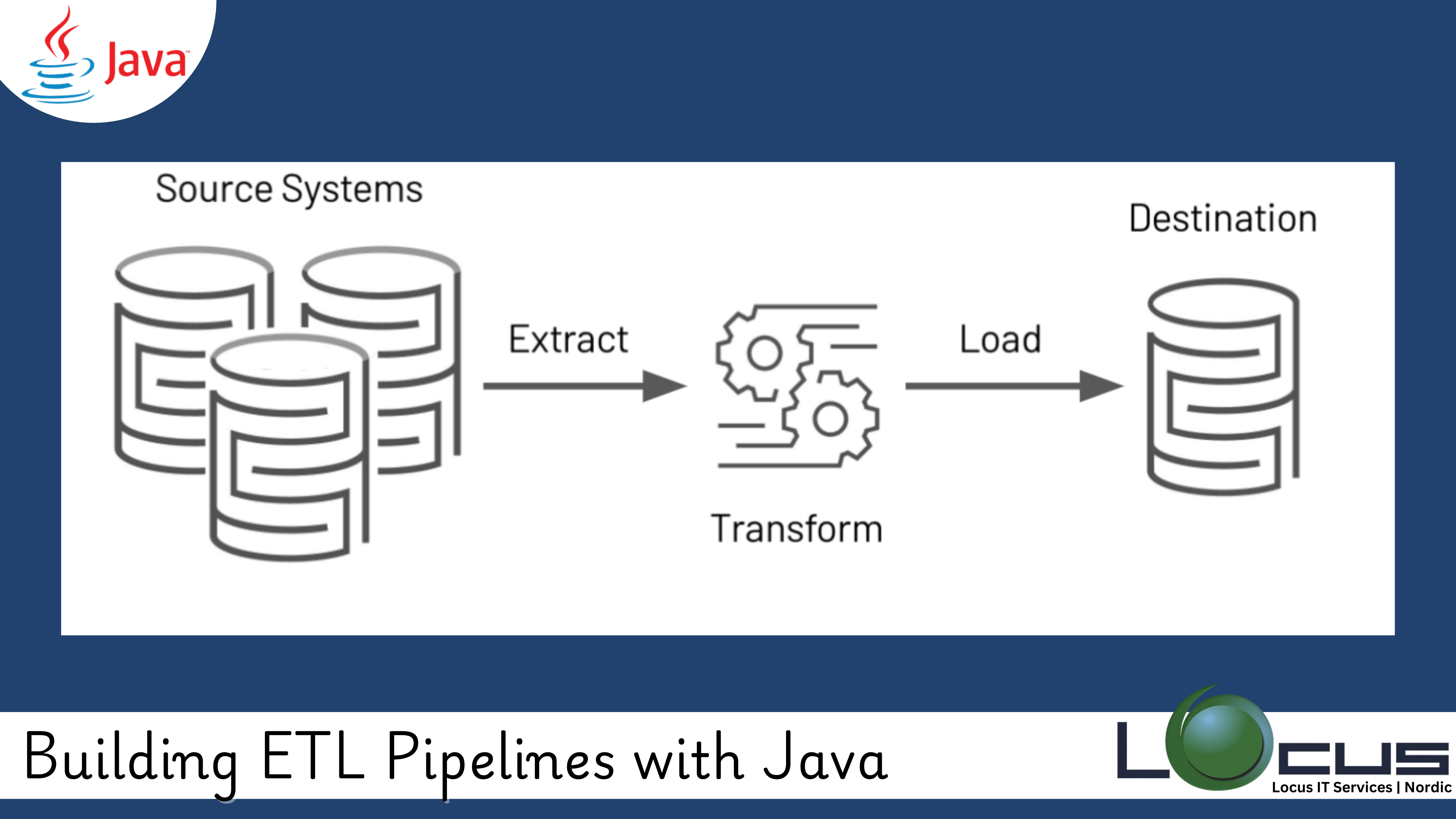
In the world of data engineering, ETL (Extract, Transform, Load) pipelines play a critical role in moving and transforming data to enable meaningful insights. Java, with its robust libraries and frameworks, is a powerful language for creating efficient and scalable ETL pipelines. This blog post explores the steps, tools, and best practices for building ETL Pipelines with Java.
What is an ETL Pipelines with Java?

An ETL Pipelines with Java is a workflow designed to move data from one or more sources to a destination, such as a data warehouse, while transforming it into a usable format. The process includes three main stages: (Ref: Java and Python for AI Workflows: Bridging Two Worlds)
- Extract: Collect data from various sources (e.g., databases, APIs, flat files).
- Transform: Clean, enrich, and reformat the data according to business rules.
- Load: Store the processed data into a target system, such as a database or data warehouse.
Java is a preferred choice for ETL development because of its:
- Scalability for handling large datasets.
- Rich ecosystem of libraries and frameworks.
- Cross-platform capabilities and integration with big data tools.
Building an ETL Pipeline with Java
1. Extracting Data
The first step in the ETL Pipelines with Java is extracting data from various sources. Java provides libraries and APIs to interact with different data formats and protocols.
Common Data Sources:
- Relational Databases (e.g., MySQL, PostgreSQL)
- APIs (REST or SOAP)
- Flat files (CSV, JSON, XML)
- NoSQL Databases (e.g., MongoDB)
Java Tools for Data Extraction:
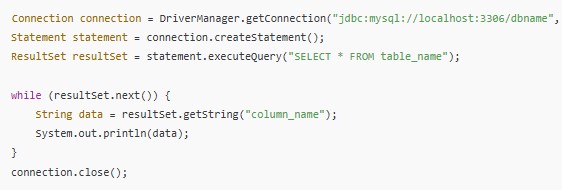
- JDBC: For connecting and querying relational databases.
- HttpURLConnection or Apache HttpClient: For extracting data from APIs.
- Jackson or Gson: For parsing JSON data.
- Apache POI: For reading and writing Excel files.
Example: Extracting data from a MySQL database.
2. Transforming Data
The transformation stage involves cleaning, filtering, and reformatting the raw data to make it meaningful. ETL Pipelines with Java offers powerful tools for transformation:
Java Features for Transformation:
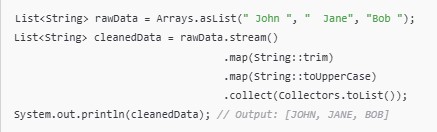
- Streams API: For processing large datasets efficiently.
- Lambda Expressions: For concise transformation logic.
- Apache Commons: For reusable utility functions.
Example: Cleaning and formatting data.
For more complex transformations, you can use libraries like:
- Apache Spark (Java API): For large-scale data transformations.
- JOOQ: For SQL-like transformations in Java.
3. Loading Data
The final stage is loading the transformed data into the target system, such as a data warehouse or cloud storage.
Java Tools for Data Loading:
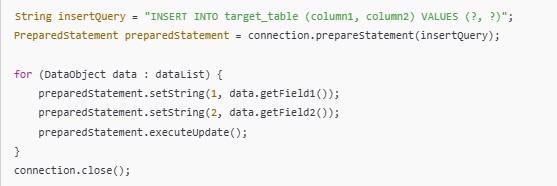
- JDBC: For inserting data into relational databases.
- Amazon SDK: For uploading data to AWS S3.
- Azure SDK: For interacting with Azure Blob Storage.
Example: Loading data into a PostgreSQL database.
Best Practices for Building ETL Pipelines with Java
- Modular Design: Split the ETL Pipelines with Java into separate modules for extraction, transformation, and loading to improve maintainability and scalability.
- Error Handling: Use robust exception handling to manage data inconsistencies and connectivity issues.
- Logging and Monitoring: Implement logging with tools like Log4j or SLF4J to track pipeline activities and errors.
- Performance Optimization: Leverage multithreading and parallel processing to handle large datasets efficiently.
- Use Frameworks: Consider frameworks like Apache Camel or Spring Batch for simplifying ETL development.
Java Frameworks for Advanced ETL Pipelines
Building ETL (Extract, Transform, Load) pipelines often requires robust frameworks to handle data workflows efficiently, especially when the volume of data or the complexity of transformations grows. Below is a detailed explanation of the mentioned Java frameworks that facilitate advanced ETL Pipelines with Java.
1. Spring Batch
Overview:
Spring Batch is a lightweight framework designed specifically for batch processing tasks, making it ideal for ETL Pipelines with Java. It is part of the larger Spring ecosystem and provides powerful abstractions for processing large volumes of data.
Key Features:
- Database Interactions: Built-in support for reading from and writing to relational databases using JDBC or JPA.
- Parallel Processing: Enables tasks to run in parallel, improving performance for high-volume data pipelines.
- Error Handling: Offers robust mechanisms to manage failures, such as retries, skips, and rollbacks.
- Scalability: Easily scalable to accommodate growing data needs.
Use Case:
You can use Spring Batch to build a pipeline that extracts customer data from a database, transforms it into a standard format, and loads it into a data warehouse for analytics.
2. Apache Camel
Overview:
Apache Camel is an open-source integration framework that facilitates routing and transformation of data across multiple systems using predefined patterns and protocols. Its flexibility makes it a popular choice for complex ETL operations.
Key Features:
- Wide Protocol Support: Supports numerous protocols like HTTP, FTP, JMS, SMTP, and more, making it versatile for various data sources.
- Routing and Transformation: Uses Enterprise Integration Patterns (EIPs) to define workflows, such as data routing, filtering, and enrichment.
- Extensibility: Allows developers to extend its functionality using custom Java components.
- Lightweight: Designed to be easily embeddable in existing Java applications.
Use Case:
You can leverage Apache Camel to extract product catalog data from an FTP server, transform it into JSON format, and route it to a REST API for a third-party service.
3. Apache Beam
Overview:
Apache Beam is a unified programming model for processing both batch and stream data. It provides a single API to build data pipelines that can run on multiple processing engines such as Apache Spark, Apache Flink, and Google Cloud Dataflow.
Key Features:
- Batch and Stream Processing: Supports both real-time and historical data processing, making it suitable for a variety of use cases.
- Portability: The same pipeline code can run on different runners, reducing dependency on a specific processing engine.
- Windowing and Triggers: Advanced features for grouping data streams by time and other dimensions.
- Fault Tolerance: Provides mechanisms for handling failures and ensuring data consistency.
Use Case:
With Apache Beam, you can create a pipeline to process customer transaction data in real-time, aggregate it, and store insights in a NoSQL database like Google BigQuery.
4. Talend Open Studio
Overview:
Talend Open Studio is a popular open-source ETL Pipelines with Java that provides a graphical user interface for designing data pipelines. Although it is a standalone tool, it supports Java-based custom scripting for complex transformations.
Key Features:
- Visual Workflow Designer: Drag-and-drop interface to design ETL pipelines without extensive coding.
- Custom Java Scripting: Allows developers to write custom Java code for specific tasks.
- Data Quality Tools: Built-in tools for validating, cleansing, and enriching data.
- Broad Connectivity: Pre-built connectors for databases, cloud platforms, APIs, and more.
Use Case:
Talend Open Studio can be used to extract sales data from Salesforce, clean it by removing duplicates, and load it into an Amazon Redshift data warehouse.
Summary Comparison
| Framework | Best For | Unique Strength | Complexity |
|---|---|---|---|
| Spring Batch | Batch processing and database ETL | Integration with Spring ecosystem | Moderate |
| Apache Camel | Integration and data routing | Protocol and system versatility | Moderate |
| Apache Beam | Batch and streaming data pipelines | Cross-engine portability | High |
| Talend Open Studio | Visual ETL design and quality tools | GUI-based development | Low |
These frameworks, individually or in combination, can be leveraged to build efficient and scalable ETL Pipelines with Java tailored to specific use cases. Each tool comes with its own strengths, so the choice depends on factors like the complexity of the ETL Pipelines with Java, team expertise, and project requirements.
Final Thoughts
Building ETL pipelines with Java is a robust and flexible approach to data engineering. By leveraging Java’s extensive ecosystem of tools and libraries, you can create scalable, efficient, and maintainable pipelines to handle complex data workflows. Whether you’re working with relational databases, APIs, or big data frameworks, Java empowers you to transform raw data into actionable insights.
Ready to unlock the power of Java for your ETL Pipelines with Java? Let Locus IT Services help you streamline your data engineering initiatives. Contact us today to learn more!