

Generative Adversarial Networks, or GANs, are one of the most exciting developments in deep learning and artificial intelligence. Introduced by Ian Goodfellow and his team in 2014, GANs have revolutionized the way we create, understand, and manipulate data. They are now essential in tasks ranging from generating realistic images and audio to creating art, advancing drug discovery, and simulating real-world environments.
In this post, we’ll dive into what Generative Adversarial Networks are, how they work, their applications, and why they are considered groundbreaking in the field of deep learning.
Outline
What Are Generative Adversarial Networks?
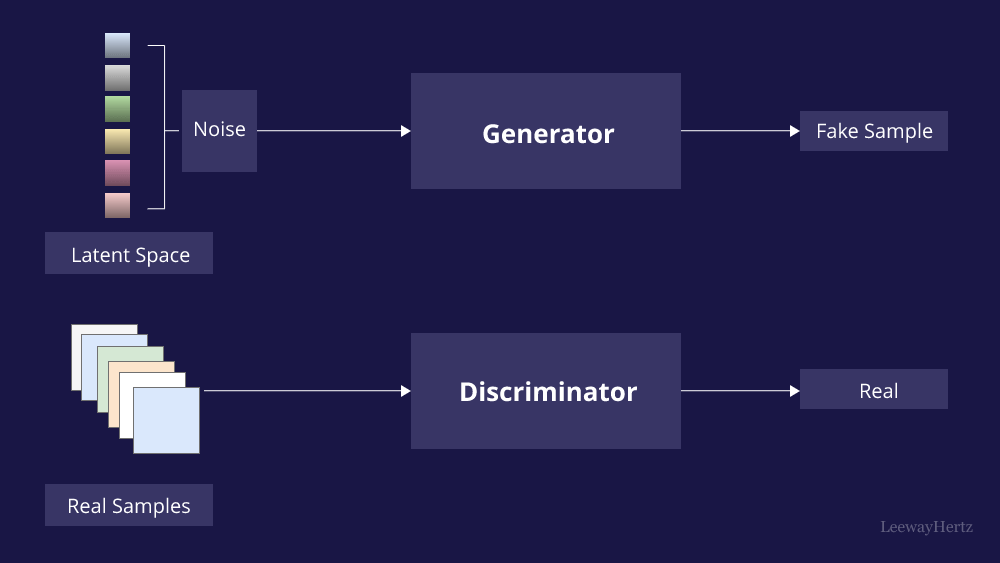
At their core, GANs are deep learning models designed to generate new, synthetic data that resembles the real data they’re trained on. They are unique because they work as a duel between two neural networks: the Generator and the Discriminator.
- Generator: This neural network’s job is to create data that mimics the real data. It starts by generating random noise and transforming it into structured data, such as an image, sound clip, or text, that resembles the real-world samples in the dataset.
- Discriminator: This network acts as a critic, evaluating the Generator’s output. The Discriminator’s role is to distinguish between real data (from the training set) and fake data (generated by the Generator). It then provides feedback to the Generator based on how well it “fools” the Discriminator.
The adversarial training loop creates a competitive setting: the Generator tries to produce increasingly realistic samples to outsmart the Discriminator, while the Discriminator continuously improves its ability to detect fakes. Over time, this competition helps the Generator produce outputs that are virtually indistinguishable from the real data.
How Generative Adversarial Networks Work: The Training Process
The training process of Generative Adversarial Networks can be broken down into these key steps:

- Generate Fake Data: The Generator produces a sample based on a random input, typically noise.
- Classify Real vs. Fake: The Discriminator evaluates both the fake data from the Generator and real data from the dataset, classifying each as either “real” or “fake.”
- Calculate Loss: Both networks calculate their losses based on the Discriminator’s classifications. The Discriminator’s goal is to minimize its error in classification, while the Generator’s goal is to maximize the Discriminator’s error in detecting fake data.
- Update and Repeat: Both networks update their parameters (weights) based on their losses, and the process repeats for many iterations. Over time, the Generator learns to produce data that is increasingly indistinguishable from real data, while the Discriminator becomes better at identifying fake data.
This iterative training leads to what is known as the Nash equilibrium—a point where the Generator produces realistic enough samples that the Discriminator has a 50% chance of guessing correctly, meaning it cannot reliably distinguish between real and generated data. (Ref: Deep Learning)
Types of Generative Adversarial Networks
GANs have evolved significantly since their inception, with various types emerging to suit different applications:
- DCGAN (Deep Convolutional GAN): Uses convolutional layers instead of fully connected layers, making it more suitable for image data.
- CGAN (Conditional GAN): Adds conditional information to both the Generator and Discriminator, allowing it to generate data based on a label or category, such as specific types of images or text.
- CycleGAN: Designed for image-to-image translation tasks, like converting photos to paintings or summer scenes to winter scenes, without the need for paired datasets.
- StyleGAN: Known for creating highly realistic images, StyleGAN introduces new controls for image generation, such as manipulating facial expressions or other image features, making it popular in applications like face synthesis.
- Wasserstein GAN (WGAN): Addresses the instability often encountered during Generative Adversarial Networks training by using a different loss function, improving convergence and training stability.
Applications of GANs
GANs have a wide range of applications across various fields. Let’s explore some of the most impactful ones:
- Image Generation and Manipulation
GANs have made a significant impact in generating photorealistic images from scratch. They’re widely used in creative applications like producing artwork, creating avatars, and even synthesizing faces that don’t exist in reality. Applications like DeepFake use Generative Adversarial Networks to manipulate videos and images to create realistic but altered versions of real people. - Image-to-Image Translation
CycleGAN and Pix2Pix, variations of Generative Adversarial Networks, are frequently used for image-to-image translation. Examples include converting sketches to photos, changing weather conditions in images, and even transforming satellite images into maps. This is particularly useful in fields like geographic information systems, real estate, and media. - Super-Resolution
GANs are used to enhance the resolution of images, a process known as super-resolution. This has applications in improving low-quality images from medical imaging, security footage, and historical photographs. - Healthcare and Drug Discovery
GANs are helping accelerate drug discovery by generating molecular structures that have desired chemical properties. GANs can simulate complex biological data, providing researchers with synthetic datasets to develop and test new treatments. - Text and Audio Generation
GANs are also used in natural language processing and audio synthesis. Models such as WaveGAN and SpecGAN have been developed for tasks like generating realistic speech, creating music, or converting text to speech. In NLP, GANs have been adapted for tasks such as text generation, sentiment analysis, and even creating chatbots. - Gaming and Simulation
In gaming, GANs are used to create realistic textures, characters, and landscapes, as well as simulate real-world environments. GANs contribute to the realism and immersion of video games, enabling developers to generate complex worlds with minimal human intervention.
Challenges and Limitations of GANs
Despite their impressive capabilities, GANs face several challenges:
- Training Instability
Training GANs is notoriously difficult due to their adversarial nature. They can suffer from problems like mode collapse, where the Generator produces limited varieties of samples, or from vanishing gradients, where the learning process stalls. - Computationally Intensive
GANs require substantial computational resources, especially for complex tasks like high-resolution image generation. Training can be time-consuming and may require specialized hardware like GPUs or TPUs. - Ethical Concerns
GANs have raised ethical questions, particularly regarding privacy and deception. Technologies like DeepFakes, which use GANs to create lifelike video simulations of real people, can be misused to create misleading content or invasion of privacy. - Evaluation Metrics
Measuring the quality of generated data is challenging. Common evaluation metrics, like Inception Score (IS) and Fréchet Inception Distance (FID), provide some insight but do not fully capture the subjective quality or diversity of generated data.
The Future of GANs
As GANs continue to evolve, researchers are developing new methods to address their limitations and expand their applications. Innovations like Progressive Growing of GANs, Self-Attention GANs (SAGAN), and BigGAN are pushing the boundaries of image quality, resolution, and scale. Additionally, hybrid models combining GANs with reinforcement learning, variational autoencoders, or transformers are beginning to show promise in advancing the versatility and robustness of GANs.
One exciting future direction is the development of Generalized Generative Models (GGMs), which could synthesize not just images or sounds but complex data forms, such as 3D models, multi-modal representations, and interactive environments. These models could transform fields such as virtual reality, autonomous driving, and simulation-based education by creating rich, realistic environments for users to interact with.
Final Thoughts
Generative Adversarial Networks have revolutionized the way we approach synthetic data generation in deep learning. Their ability to create realistic images, audio, text, and even entire virtual worlds has opened new possibilities in entertainment, healthcare, design, and beyond. While challenges like training instability and ethical implications remain, GANs continue to push the boundaries of AI and reshape our understanding of machine creativity and data generation.
With continued research and development, GANs promise to be a foundational technology in deep learning, enabling machines not only to learn from data but to create it.