

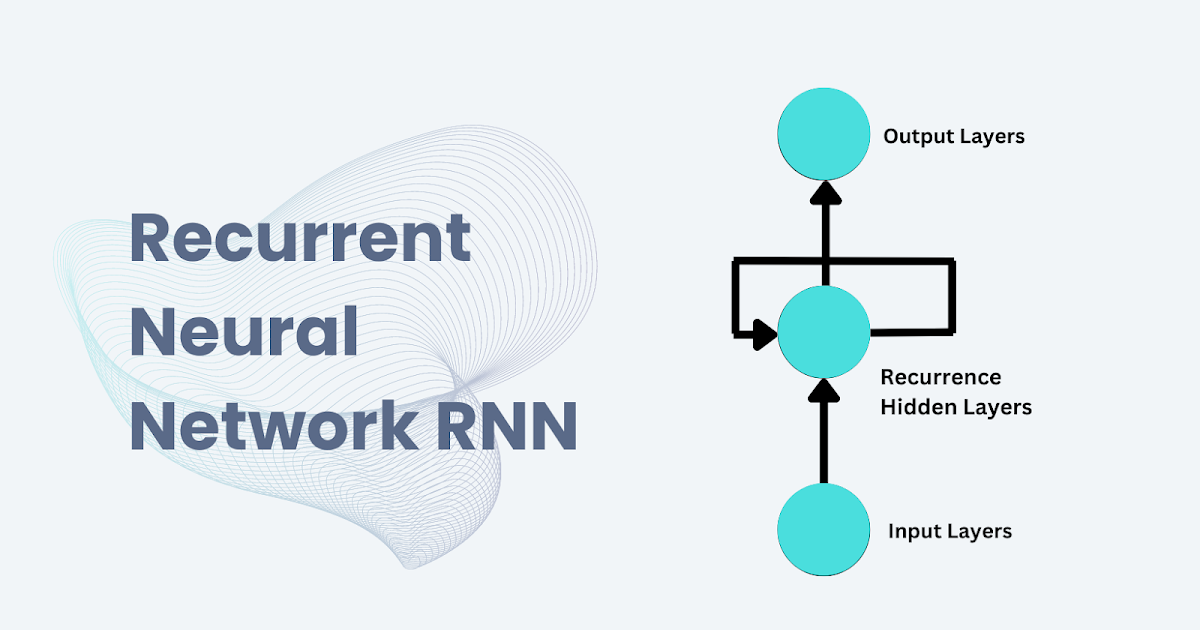
Recurrent Neural Networks (RNNs) are a powerful class of deep learning models designed to work with sequential data. Unlike traditional neural networks, which assume that each input is independent of others, RNNs excel at processing data with inherent sequences and dependencies, such as time-series data, text, and audio. This unique characteristic makes RNNs essential for applications where context and order matter, such as language translation, speech recognition, and financial forecasting. In this post, we’ll dive into the fundamentals of RNNs, explore their key components, and examine their real-world applications and limitations.
Outline
What is a Recurrent Neural Network (RNN)?
An RNN is a type of neural network that is particularly suited for sequential data. While traditional neural networks process inputs independently, Recurrent Neural Network introduce loops within the network, allowing them to retain information from previous inputs. This “memory” enables Recurrent Neural Network to capture temporal dependencies and make predictions based on previous context, making them ideal for tasks where understanding previous inputs is crucial.
The defining feature of an RNN is its hidden state, which is updated as each input in the sequence is processed. This hidden state acts as a memory, capturing information from past steps to inform predictions on future steps. However, vanilla RNNs have limitations, including difficulty in capturing long-term dependencies due to issues like vanishing and exploding gradients.
Key Components of RNNs
- Hidden State
The hidden state is the memory component of the RNN. At each time step, the network updates its hidden state based on the input and the previous hidden state. This hidden state accumulates information from past steps, which the network uses to inform predictions on future inputs. - Recurrent Loop
RNNs have a recurrent structure that enables information to persist across time steps. Each time step’s output becomes part of the input for the next time step, creating a feedback loop. This structure allows RNNs to learn temporal dependencies, making them well-suited for sequential data tasks. - Activation Functions
RNNs use activation functions, such as hyperbolic tangent (tanh) or Rectified Linear Unit (ReLU), to introduce non-linearity and capture complex relationships within the data. However, training traditional RNNs with these functions can lead to vanishing or exploding gradients, which hinders learning for long sequences. - Backpropagation Through Time (BPTT)
Training RNNs involves a process called backpropagation through time (BPTT), which adjusts weights across multiple time steps. In BPTT, the model calculates the error at each time step, then uses gradient descent to minimize this error across all time steps. This process enables the RNN to learn from sequential dependencies, although it can be computationally intensive.
Variants of RNNs: LSTMs and GRUs
To address the limitations of standard RNNs, researchers developed more advanced architectures like Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs). These architectures are specifically designed to handle long-term dependencies more effectively by using gating mechanisms.
- Long Short-Term Memory (LSTM)
LSTMs introduce memory cells with gates that control the flow of information. These gates—input, forget, and output gates—allow the network to retain or discard information based on relevance. This structure helps LSTMs capture long-term dependencies, making them ideal for tasks like language modeling and machine translation. - Gated Recurrent Unit (GRU)
GRUs are a simplified version of LSTMs with only two gates: the reset gate and the update gate. GRUs have fewer parameters than LSTMs, making them more computationally efficient while still effectively capturing long-term dependencies. They are often used in applications that require less memory overhead but still benefit from RNN capabilities.
How RNNs Work: An Example in Language Modeling
Let’s walk through a simplified example of how an RNN works in the context of language modeling:
- Input Sequence: A sentence, such as “The dog chased the cat,” is tokenized into a sequence of words.
- Embedding Layer: Each word is converted into a vector representation, capturing semantic meaning.
- Hidden State Update: The RNN processes each word in the sequence, updating its hidden state at each step to retain information about the previous words. For instance, when it encounters “chased,” the RNN has memory of “dog,” helping it understand the context.
- Prediction: After processing the sequence, the RNN uses the final hidden state to predict the next word in the sentence or classify the sequence (e.g., positive or negative sentiment).
- Backpropagation Through Time: The RNN calculates the error between its predictions and the actual output, updating weights across the sequence to improve performance in future predictions.
Applications of RNNs in Industry
RNNs have a wide range of applications across industries due to their ability to model sequential data and understand context. Here are some notable use cases:
- Natural Language Processing (NLP)
In NLP, RNNs are used for language modeling, machine translation, text generation, and sentiment analysis. For example, RNNs enable chatbots to understand and respond to user queries by considering previous interactions, allowing for coherent and context-aware responses. (Ref: Natural Language Processing) - Speech Recognition
RNNs are fundamental in speech recognition systems, such as those used by virtual assistants like Siri and Google Assistant. By capturing the temporal structure of spoken language, RNNs can convert audio into text and provide real-time transcription and command recognition. - Financial Forecasting
In finance, RNNs are used to analyze time-series data, such as stock prices and currency exchange rates. By understanding historical trends and patterns, RNNs can provide valuable insights into future market behaviors, supporting trading strategies and risk management. - Healthcare and Medical Diagnosis
RNNs can process patient data over time, helping to predict health outcomes or diagnose diseases based on past medical records. For instance, RNNs are used in predicting patient readmissions, assisting doctors in making data-driven decisions for patient care. - Anomaly Detection
In cybersecurity and fraud detection, RNNs analyze sequences of user behavior or network traffic to detect anomalies. These networks can identify suspicious patterns, alerting to potential security breaches or fraudulent transactions. (Ref: Deep Learning in Self-Supervised Learning (SSL))
Advantages of RNNs in Deep Learning
- Temporal Dependencies: RNNs excel at modeling dependencies within sequences, making them ideal for time-series analysis, speech processing, and other sequential tasks.
- Dynamic Input Length: Unlike traditional networks, RNNs can handle inputs of varying lengths, allowing them to process flexible sequences, whether a short sentence or a long document.
- Sequential Processing: By processing data in steps, RNNs can understand context, leading to improved accuracy in applications where previous information impacts future predictions.
Challenges and Limitations of RNNs
Despite their strengths, RNNs face some challenges:
- Vanishing and Exploding Gradients
Standard RNNs suffer from vanishing and exploding gradients, making it difficult for them to learn long-term dependencies. This issue is largely addressed by using LSTM and GRU architectures, which are better suited for handling longer sequences. - Computational Complexity
Training Recurrent Neural Network can be computationally intensive, especially for long sequences or large datasets. BPTT, the training algorithm for Recurrent Neural Network, requires significant memory and processing power, making it challenging for real-time applications. - Short-Term Memory
Traditional Recurrent Neural Network have a limited ability to remember information over long sequences. This issue can limit their effectiveness in tasks that require a long history of context, such as narrative understanding in language models.
Future Directions for RNNs
While LSTMs and GRUs have improved Recurrent Neural Network capabilities, recent advancements in deep learning, such as Transformers, offer promising alternatives. Transformers use an attention mechanism that processes entire sequences simultaneously, addressing some limitations of Recurrent Neural Network, particularly in long-sequence processing. However, Recurrent Neural Network remain valuable for real-time applications and tasks with limited data, where their structure provides unique benefits.
Final Thoughts
Recurrent Neural Networks have brought significant advancements to AI by enabling the processing and understanding of sequential data. With applications ranging from language processing to finance and healthcare, Recurrent Neural Network continue to be instrumental in driving innovation. Despite their challenges, Recurrent Neural Network are a valuable tool in any deep learning toolkit, particularly for tasks where understanding sequence and context is crucial.
As technology advances, we can expect further refinement of Recurrent Neural Network and the development of hybrid models that combine Recurrent Neural Network with other architectures like CNNs and Transformers. For businesses and researchers, understanding Recurrent Neural Network and their applications is key to leveraging AI’s full potential in a data-driven world.