

Natural Language Processing (NLP) has transformed our ability to process and understand human language through applications like chatbots, voice assistants, sentiment analysis, and machine translation. But building NLP models that deliver high accuracy and contextual understanding requires more than just basic training. Model optimization and fine-tuning are essential steps that help NLP models perform better, adapt to specific tasks, and provide more accurate results.
In this blog post, we’ll explore why model optimization and fine-tuning are crucial for NLP, strategies to enhance model performance, and tips for making your NLP models more adaptable and effective.
Summary of Contents
Why Optimization & Fine-Tuning Matter in NLP
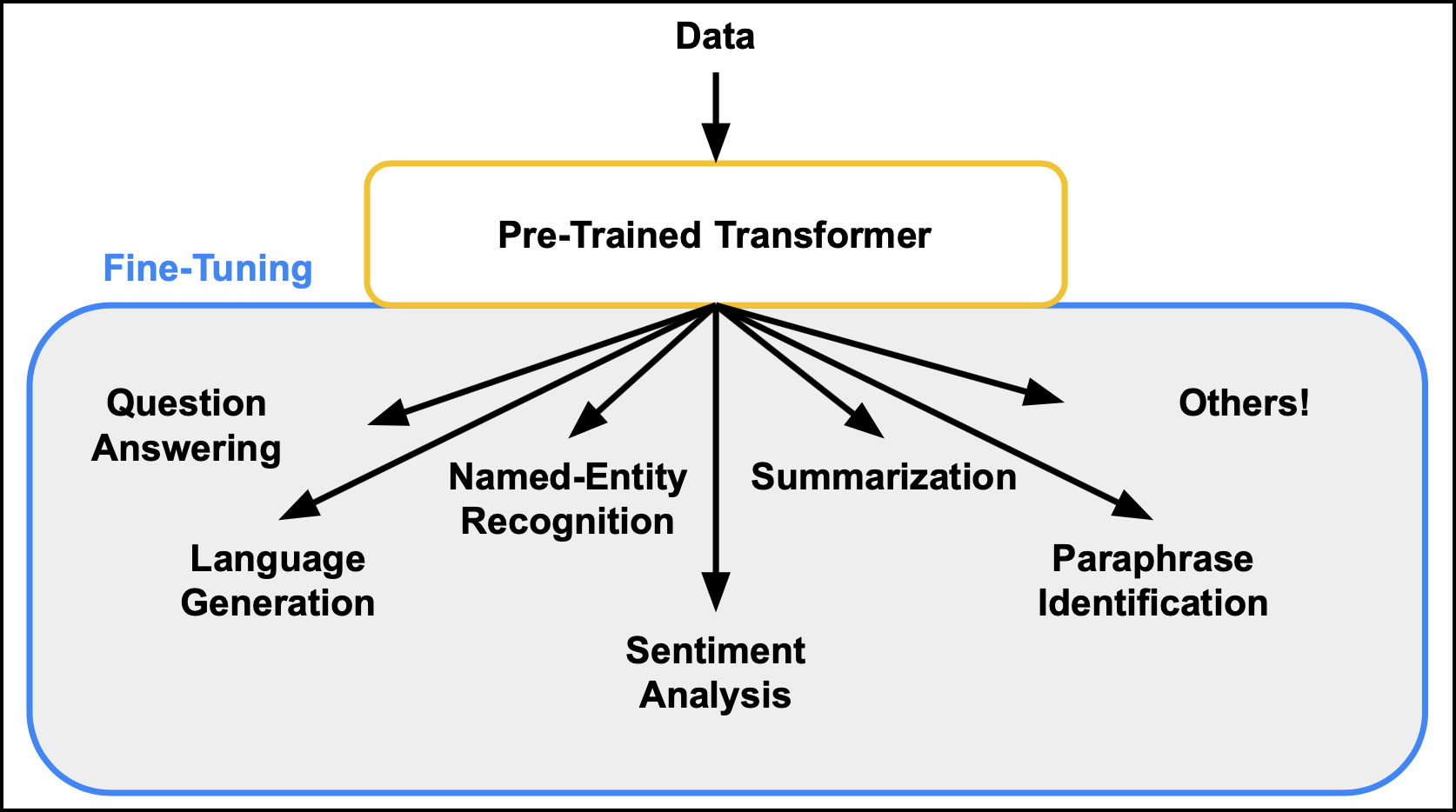
Modern NLP models, particularly large language models (LLMs) like BERT, GPT, and T5, are pre-trained on massive datasets to understand general language patterns. However, these models often need adjustments, or “fine-tuning,” to excel in specific applications. Fine-tuning and optimization make NLP models more robust by:
- Improving accuracy: Tailoring models to a specific domain, such as healthcare or finance, increases their reliability in interpreting specialized vocabulary and contexts.
- Reducing computational costs: Optimizing models can make them faster and more efficient, which is crucial for applications requiring real-time processing.
- Enhancing user experience: When models perform tasks more accurately and efficiently, user satisfaction increases, making the technology more valuable.
Key Strategies for NLP Model Optimization & Fine-Tuning
There are several effective techniques to optimize and fine-tune NLP models for better performance. Let’s dive into some of the most impactful strategies:
1. Transfer Learning
Transfer learning leverages pre-trained models as a foundation, reducing the time and resources required to train a new model from scratch. Instead of training a model from the ground up, transfer learning builds upon existing knowledge, adapting it for a specific task. (Ref: NLP in Document Summarization)
How it works:
- Choose a pre-trained model, like BERT, RoBERTa, or GPT.
- Fine-tune this model using a smaller, task-specific dataset.
- This approach enables the model to retain general language understanding while tailoring it for particular applications.
Benefits: Transfer learning accelerates the training process, especially for tasks with limited data, and results in high accuracy with minimal resources.
2. Data Augmentation
Quality training data is key to building effective NLP models, but gathering and labeling data can be costly and time-consuming. Data augmentation increases the amount of available data by creating variations of existing text, which improves model generalization.
Common Data Augmentation Techniques:
- Synonym Replacement: Substitute words with their synonyms to create diverse sentence structures.
- Back-Translation: Translate text into another language and then back to the original language, introducing subtle variations.
- Random Insertion or Deletion: Adding or removing random words to simulate different sentence structures.
Benefits: Data augmentation helps models understand language nuances, making them more adaptable to variations in phrasing and terminology.
3. Hyperparameter Tuning
Hyperparameters, such as learning rate, batch size, and the number of training epochs, play a vital role in determining how well an NLP model performs. Tuning these hyperparameters can significantly impact the model’s accuracy and training efficiency.
How to Tune Hyperparameters:
- Grid Search: Test different combinations of hyperparameters within a predefined range.
- Random Search: Randomly sample hyperparameter values and observe the model’s performance to identify optimal settings.
- Bayesian Optimization: Use probabilistic models to predict the best hyperparameter configurations based on previous iterations.
Benefits: Well-tuned hyperparameters lead to faster convergence, reduced overfitting, and improved overall model performance.
4. Domain-Specific Fine-Tuning
For specialized applications, general NLP models may struggle with domain-specific terminology and concepts. Fine-tuning these models on domain-specific data allows them to excel in niche areas, such as legal or medical text processing.
Approach:
- Collect a dataset relevant to your specific industry.
- Fine-tune the pre-trained model using this dataset, allowing it to learn the context and terminology.
- Validate the model on domain-specific tasks to measure improvements in accuracy and relevance.
Benefits: Domain-specific fine-tuning enhances the model’s ability to interpret specialized vocabulary, improving precision and contextual understanding in focused applications.
5. Pruning and Quantization
NLP models, especially large ones, can be computationally expensive. Pruning and quantization are techniques that reduce model size without compromising too much accuracy.
- Pruning: Reduces the number of model parameters by removing less significant connections, decreasing model complexity.
- Quantization: Converts model weights from higher precision (e.g., 32-bit) to lower precision (e.g., 8-bit), reducing memory usage and speeding up computations.
Benefits: These optimization techniques make models lighter, faster, and more resource-efficient, which is essential for deploying NLP applications on mobile devices or low-power environments.
6. Knowledge Distillation
Knowledge distillation involves training a smaller model, or “student model,” to replicate the behavior of a larger, more complex “teacher model.” The student model learns by imitating the teacher’s output, retaining similar accuracy levels with reduced complexity.
How it works:
- Use a large, pre-trained model as the teacher.
- Train a smaller model to mimic the teacher’s predictions, learning its behavior.
- Evaluate the student model to ensure it delivers comparable performance.
Benefits: Knowledge distillation reduces model size and computational demands, making it ideal for real-time applications that require quick responses.
Practical Applications of NLP Model Optimization
The benefits of optimizing and fine-tuning NLP models extend across a wide range of applications, from customer service to healthcare:
- Sentiment Analysis for Brand Monitoring: Fine-tuning a sentiment analysis model on data specific to a brand’s industry can improve the accuracy of customer feedback interpretation, offering precise insights for marketing teams.
- Healthcare Document Processing: Domain-specific fine-tuning can help NLP models accurately process patient records, extracting meaningful information with higher precision.
- Chatbot Performance Enhancement: Optimized NLP models lead to faster response times and improved understanding of customer queries, providing more seamless and accurate chatbot interactions.
- Financial News Analysis: Fine-tuning a model to recognize financial jargon improves the accuracy of insights drawn from news articles, stock reports, and market analysis.
Tips for Effective NLP Model Optimization & Fine-Tuning
- Start Small: Begin with a pre-trained model and a manageable dataset to understand the initial model’s performance. This approach reduces resource demands and provides a baseline for optimization.
- Regularly Validate Models: Frequently evaluate models on validation sets to ensure that adjustments are genuinely enhancing accuracy and efficiency.
- Use Cross-Validation: Cross-validation, particularly in smaller datasets, ensures that the model is not overfitting and can generalize well.
- Experiment with Ensemble Models: Combining multiple models can sometimes yield better performance than a single, optimized model, especially in complex tasks.
- Automate Hyperparameter Tuning: Tools like Hyperopt or Optuna can automate hyperparameter searches, allowing you to explore a larger configuration space efficiently.
Challenges in NLP Model Optimization
Despite the advantages, optimizing and fine-tuning NLP models can be challenging. Some common hurdles include:
- Resource Constraints: Training and fine-tuning large models require high computational power, which can be expensive and time-consuming.
- Data Scarcity: High-quality, domain-specific data is not always available, making it difficult to fine-tune models effectively.
- Overfitting Risks: Fine-tuning on small datasets may lead models to memorize patterns instead of generalizing, leading to poor performance on new data.
- Complexity in Deployment: Deploying optimized models on different platforms may require additional adjustments, especially in resource-constrained environments like mobile devices.
The Future of NLP Optimization and Fine-Tuning
As NLP models grow more sophisticated, the future of model optimization and fine-tuning holds exciting possibilities:

- Self-Optimizing Models: Future models may incorporate self-optimization techniques, adjusting hyperparameters and structures dynamically based on real-time feedback.
- Few-Shot and Zero-Shot Learning: Advancements in transfer learning could enable models to handle new tasks with minimal or no additional data, reducing the need for extensive fine-tuning.
- Smarter Model Compression: Innovations in model pruning and quantization will continue, making it easier to deploy NLP models on edge devices and low-power systems.
- Task-Agnostic Models: As general-purpose models like GPT and T5 become more advanced, we may see models capable of performing a variety of tasks without specific fine-tuning, simplifying the deployment process.
Final Thoughts
Model optimization and fine-tuning are vital for creating NLP applications that are not only accurate but also efficient, flexible, and responsive to user needs. By adopting techniques like transfer learning, hyperparameter tuning, pruning, and domain-specific fine-tuning, organizations can tailor NLP models to deliver impressive results across diverse applications.
As advancements continue, the line between general-purpose and task-specific models will blur, making NLP technologies more accessible and impactful across industries. Investing in model optimization today will ensure that your NLP applications are ready to meet the demands of tomorrow.